How many of us have spent the better part of an evening trying to choose what movie to watch? Imagine a world where you wouldn’t have to choose. Instead, content would be created in real time based on your reactions. Sounds like science fiction, right? Well, in this post we will walk through how to do exactly this. Using the Azure AI stack we will build a simple application that uses facial expressions to create real time content.
Generative AI holds tremendous potential for solving a wide range of complex problems. Unlike traditional AI models that are focused on recognising patterns and making predictions based on existing data, generative AI goes a step further by creating new, original content.
Global cloud vendors such as Azure, Google and AWS, are participating in the LLM battle. They want to develop and offer GenAI solutions to enrich their already rich ecosystems. By seamlessly integrating generative AI capabilities into their existing services, these companies can offer comprehensive AI solutions to their customers. We recently earned the AI and Machine Learning in Microsoft Azure specialisation, so in this post, we will use the Azure AI stack. Azure has some of the most mature solutions on the market and we generally recommend utilising these kinds of solutions as they are a great way to kickstart your generative AI project.
General idea of the application
The goal of our application is to create real time content based on sentiment analysis of facial expressions. We want to create a service where a person can start to read a story and based on the reaction of the reader the story will be altered in real time. To build such an application we need to apply several steps. From here it will become rather technical.
Image capture and retrieval of facial expression
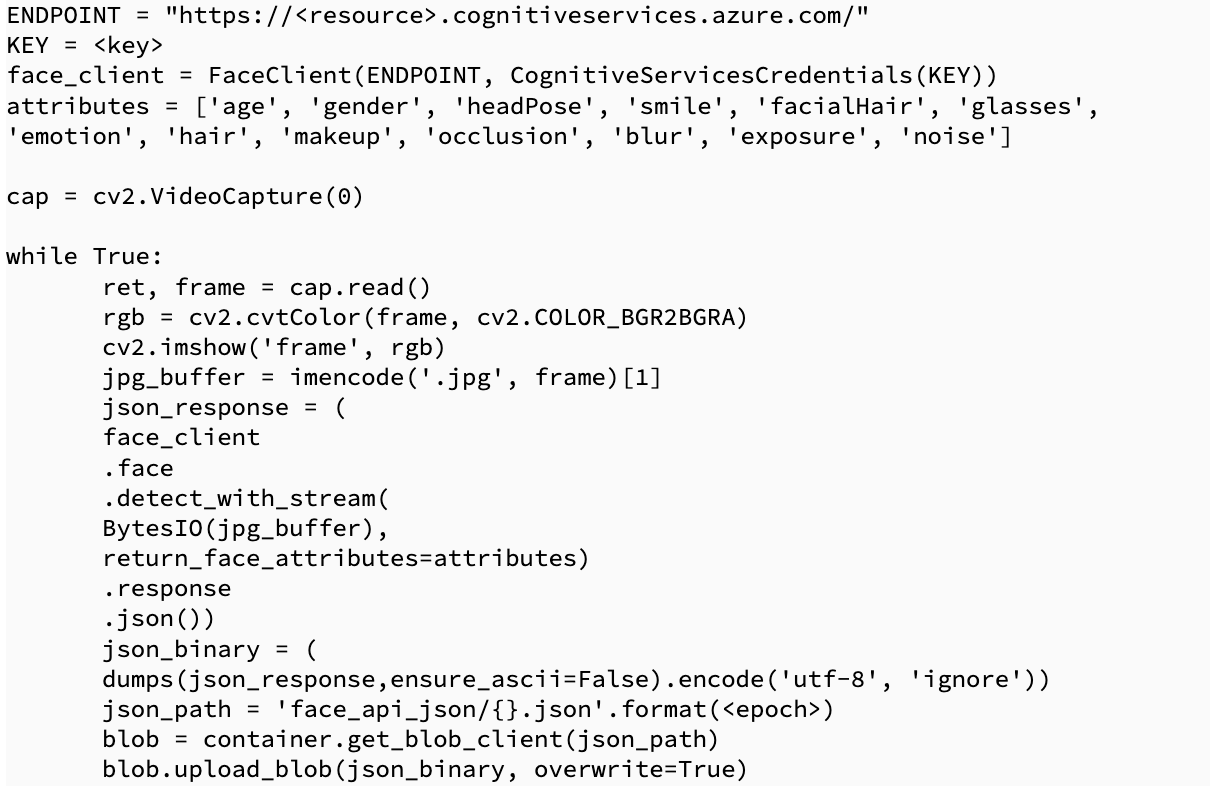
As mentioned, we are using the Azure cloud platform. Below we have created a Python script which will be running on an edge device in an infinite loop. The edge device takes a picture, calls the Azure Cognitive Services FaceAPI endpoint and then writes the sentiment response to an Azure Blob Storage container.
Continuous data ingestion using Azure Databricks and Spark Streaming
I will use the Spark framework for processing data from here on. Not because we necessarily need it for this use case but… Who doesn’t love a smooth stream of data?
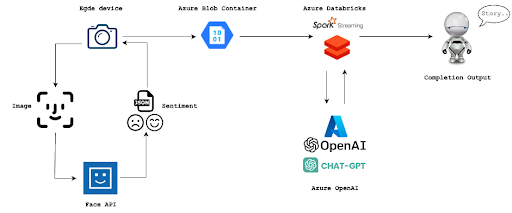
Jokes aside, imagine a use case where it isn’t one reader but a crowd of people (read faces) listening to a speaker. To spice it up even further, let’s say that there is not one single crowd but multiple crowds at different places around the globe at the same time. If there would be crowds of 10.000 people at 10.000 different places, then we would have 100 million sentiments to be processed every second or two. The parallelism and distributed processing capabilities of Spark allow it to handle high-volume data streams efficiently. The below code ingests data from cloud storage and writes it to a delta table as a stream.

Accessing Azure OpenAI LLM in a stream
After streaming the data into a delta table another stream takes over. This stream will access the model through Chat Completion API which is part of Azure OpenAI suite, use the sentiment and message history in the prompt and write the response to another delta table. The output would be the sentiment-based generated story. Building up the message history (read message list), the conversation style would look like this:
- System message (for context, instructions, or other information relevant to your use case.)
- Prompt message – from user
- Response – from assistant
- Prompt message – from user
- And so on…
The message list would then be the input message to the model. Below is the initial message list that will grow bigger and bigger as the story continues, i.e., the user and assistant conversation will be appended to this list.

Below we will create a user-defined function that adds the sentiment-based user message to the message list, asks the model for completion using the message list then adds the response to the message list and returns the response.
Above UDF takes a user message as input, we will create a user-defined function that generates it. It takes the sentiment as input and creates the user message depending on the emotion of it.
Now we’re ready to spin up the stream and give life to our AI storyteller. We using a processBatch() function for several reasons. The processBatch() function in Databricks Spark Structured Streaming is used when you need to perform batch processing within a streaming application. When making API calls inside a Spark Structured Streaming application, you might encounter situations where it is more practical to collect a batch of data before making the API call. A few reasons are API Rate Limiting, API Efficiency, Atomicity and Consistency.
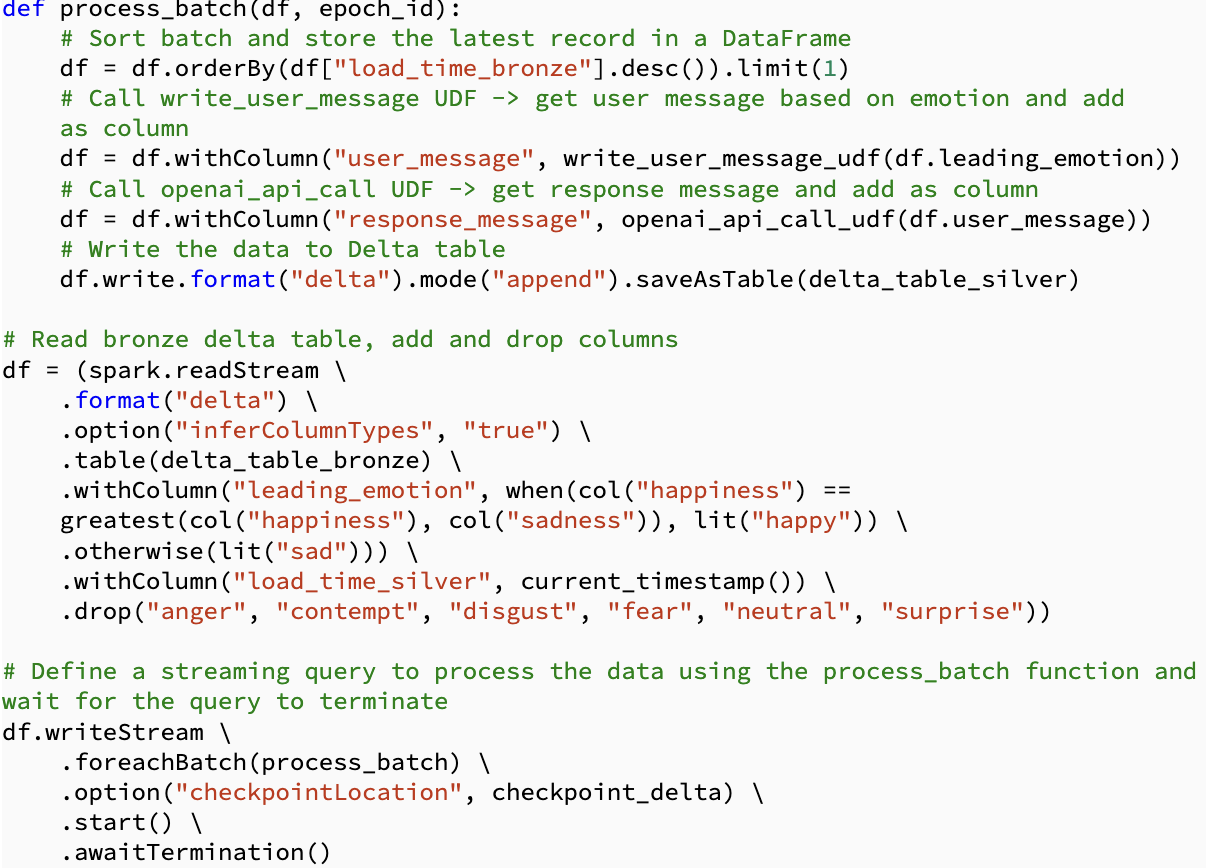
Data flow from image to completion
Now it is clearer how the data flows through the different components.
Let’s draw up the solution.
Learnings
As we experienced in this post, LLM-based applications are easy to spin up using already existing components from the cloud vendors. However, the biggest effort lies in making the application useful for the users and getting the model behind the UI to perform as expected.
One should consider fine-tuning the LLM to make it more relevant and effective for this particular use case. This kind of application can be incredibly helpful in various aspects of everyday life, and not only for individuals eager to read customised stories but also in corporate or public use cases such as generating speeches, creating customised marketing campaigns or joke generation for a stand-up comedian. Of course in real-time and mood adjusted.
This application’s latency from a picture taken to the generated story was about 6-7 seconds which one could say is near real-time.
There were also some technical learnings. During the development, we experienced that keeping track of the session and retaining the prior responses from the model was a bit of a hassle when processing data using a Spark stream. As a matter of fact, the message_list global variable was not able to retain its value between batches. Apparently, when using the processBatch() function in Spark Structured Streaming, global variables may not retain their values between batches because each batch is processed independently.
Thanks for reading!
Author

Jens Jakobsson
Data Scientist, Solita