In our recently published study [1], I and my colleagues Kari Antila and Vilma Jägerroos examined the possibility of predicting the burden of healthcare using machine learning methods. We used data on symptoms and past healthcare utilisation collected in Finland. Our results show that COVID-19-related healthcare admissions can be predicted one week ahead with an average accuracy of 76% during the first wave of the pandemic. Similar symptom checkers could be used in other societies and for future epidemics, and they could provide an opportunity to collect data on symptom development very rapidly – and at a relatively low cost.
The rapid spread of the SARS-CoV-2 virus in March 2020 presented challenges for nationwide assessment of the progression of the COVID-19 pandemic. In Finland, Solita helped to add a COVID-19 symptom checker to a pre-existing national, CE-marked medical symptom checker service ©Omaolo. The Omaolo COVID-19 symptom checker achieved considerable popularity immediately after its release, and the city of Helsinki, for example, has estimated annual savings of 2.5 million euros from its use. Although there have been studies about how well symptom checkers perform as clinical tools, their data’s potential for predicting epidemic progression, to our knowledge, has not yet been studied.
For this purpose, we developed a machine learning pipeline in the Finnish Institute for Health and Welfare’s (THL) computing environment for automated model training and comparison. The models created by us were retrained every week using time-series nested cross-validation, allowing them to adapt to the changes in the correlation of the symptom checker answers and the healthcare burden. The pipeline makes it easy to try new models and compare the results to previous experiments.
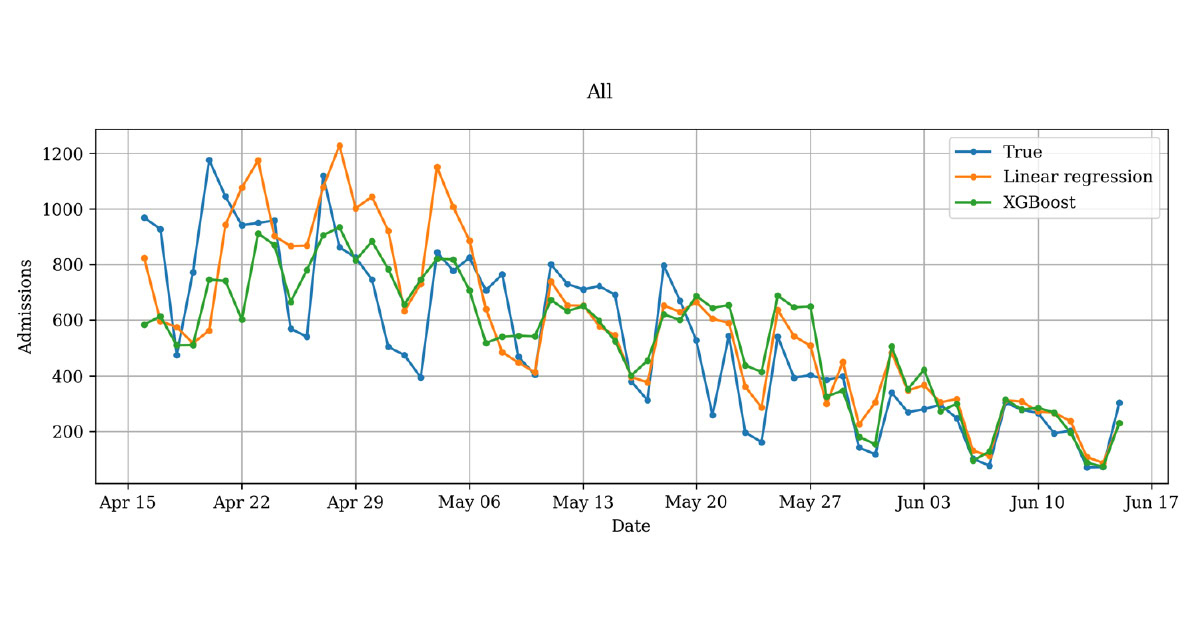
We decided to compare linear regression, a simple and traditional method, to XGBoost regression, a modern option with many hyperparameters that can be learned from the data. The best linear regression model and the best XGBoost model (shown in the figure) achieved mean absolute percentage error of 24% and 32%, respectively. Both models get more accurate over time, as they have more data to learn from when the pandemic progresses.
COVID–19–related admissions predicted by linear regression and XGBoost regression models, together with the true admission count during the first wave of the pandemic in 2020.
Our results show that a symptom checker is a useful tool for making short-term predictions on the healthcare burden due to the COVID-19 pandemic.
Symptom checkers provide a cost-effective way to monitor the spread of a future epidemic nationwide and the data can be used for planning the personnel resource allocation in the coming weeks.
The data collected with symptom checkers can be used to explore and verify the most significant factors (age groups of the users, severity of the symptoms) predicting the progression of the pandemic as well.
You can find more details in the publication [1]. The research was done in collaboration with the University of Helsinki, the Finnish Institute for Health and Welfare, Digifinland Oy, and the IT Centre for Science, and we thank everyone involved.
If you have similar register data and would like to perform a similar analysis, get in touch with me or our team and we can work on it together!
References
[1] Limingoja L, Antila K, Jormanainen V, Röntynen J, Jägerroos V, Soininen L, Nordlund H, Vepsäläinen K, Kaikkonen R, Lallukka T. Impact of a Conformité Européenne (CE) Certification–Marked Medical Software Sensor on COVID-19 Pandemic Progression Prediction: Register-Based Study Using Machine Learning Methods. JMIR Form Res 2022;6(3):e35181, doi: 10.2196/35181, PMID: 35179497