The world news cycle was caught this year with generative AI as the capabilities of ChatGPT and other generative AI piqued the interest of many, stunned others with their capabilities, and scared some to talk about the potentially existential threats of this technology. Almost as soon as articles about the possibilities began to emerge, so did articles about the security threats this poses.
Employees in different companies leaked proprietary information to these tools, the models produced very convincing falsehoods that brought trouble to users, and data used to train these models leaked information that should have remained private. While the hype goes on, those of us working in the field are testing the technology. We are trying it out, thinking of use cases, and ways of safeguarding solutions that allow us to create long-term business value with these new tools.
This is still machine learning
While the efficacy and possibilities of this technology are changing fast, the foundations of it are not new. Machine learning algorithms as well as the fundamentals of generative AI have been around for decades. These are not unknown quantities for professionals. There are easily available best practices of MLOps to help safeguard the models and systems they are a part of. We have a solid and customer-tested framework in use at Solita for instance for this kind of use. These models are also utilised in applications and systems where a big part of keeping it safe is through best practices in DevOps.
Independent of the exact nature of the ML or genAI algorithm, keeping your solutions and systems safe comes down to three main parts. The attack surface of an AI solution is the total sum of the vulnerabilities these three parts are exposed to. And while it can be daunting, it is also something that is not new to people working to produce high-quality solutions with long-term business value.
The foundations of each ML system: the data
The first of these parts is the data. There can never be machine learning without data and any machine learning algorithm is only as good as the data that was used to train and re-train it. The data is also one of the more difficult things to keep safe for machine learning, especially generative AI, as the foundational models are trained on data scraped from the internet. As we all know, anyone can add data saying just about anything to the internet. So, the quality of this data is quite questionable.
Open data sets can be poisoned, which means that some data is added to the dataset used to train or re-train a model to change its logic in some way. For instance, recommendation system data can be poisoned by fake accounts to upvote, downvote, or promote certain products instead of others. Chatbots trained on Twitter data can be poisoned to spout offensive content, as Microsoft discovered with the chatbot Tay already in 2016.
In a business case, this does not need to be a cause to abandon this technology. It, however, needs to be a point of serious thought and consideration. It requires that the role given to the algorithm considers this fact. Basically, it means that a foundational model such as the ChatGPT cannot be an expert system responsible for providing facts unless those facts are provided to it by the company, and it is prompted to stick to the company-provided facts and not stray from them. It requires some retraining on the company’s data. It will for sure require careful thought in how the model is used. We’ll return to this idea of roles a bit later.
If the data used is proprietary and kept safe, the data poisoning requires gaining access to these protected systems and data poisoning becomes much harder. Then it is more a question of safeguarding and encrypting the data at rest and in transit, masking and encrypting especially sensitive data and so forth.
The ‘brains’ of the system: the model
The second part of the system is the algorithm, aka the model, itself. It is possible to reverse engineer the model if the architecture of the ML solution allows for this, putting proprietary information at risk of leaking. For instance, an unprotected API endpoint can be queried repeatedly to infer the point where a yes becomes a no in a classification model. With a generative AI, several companies have already made it to the press with news articles on how the staff has added proprietary information to the models that have then leaked.
With the proper architecture planning, model choices, and decisions on how to serve the model, most of these risks are avoidable. The choice of the model helps avoid many of the rest. The questions to be answered here are, for instance, who needs access to the model, what exact problem is the model trying to solve, what is the best model for the job, how is it served, where the data used to periodically retrain it comes from and has that been validated and cleaned, and so forth.
Safeguarding the model and making it fit for purpose is very doable if one knows what they are doing, and the use case allows it. Some use cases require the model to be served through APIs open to the internet or re-trained by using data fed to it by users, which can then cause some heartburn and grey hairs for the ones responsible for the model’s security.
The entire thing that is needed to actually use the model: the system
The third part of the machine learning solution is the system itself. When a model is put into production, it is never just about the model. There are a lot of other things needed around the model to make it work as planned. These include data cleaning and validation, model serving infrastructure, monitoring, access management, usage authorisation, resource management, how is the usage monitored and logged, retraining pipelines, and so forth. The image below describes this with the ML-specific code in the little red box.
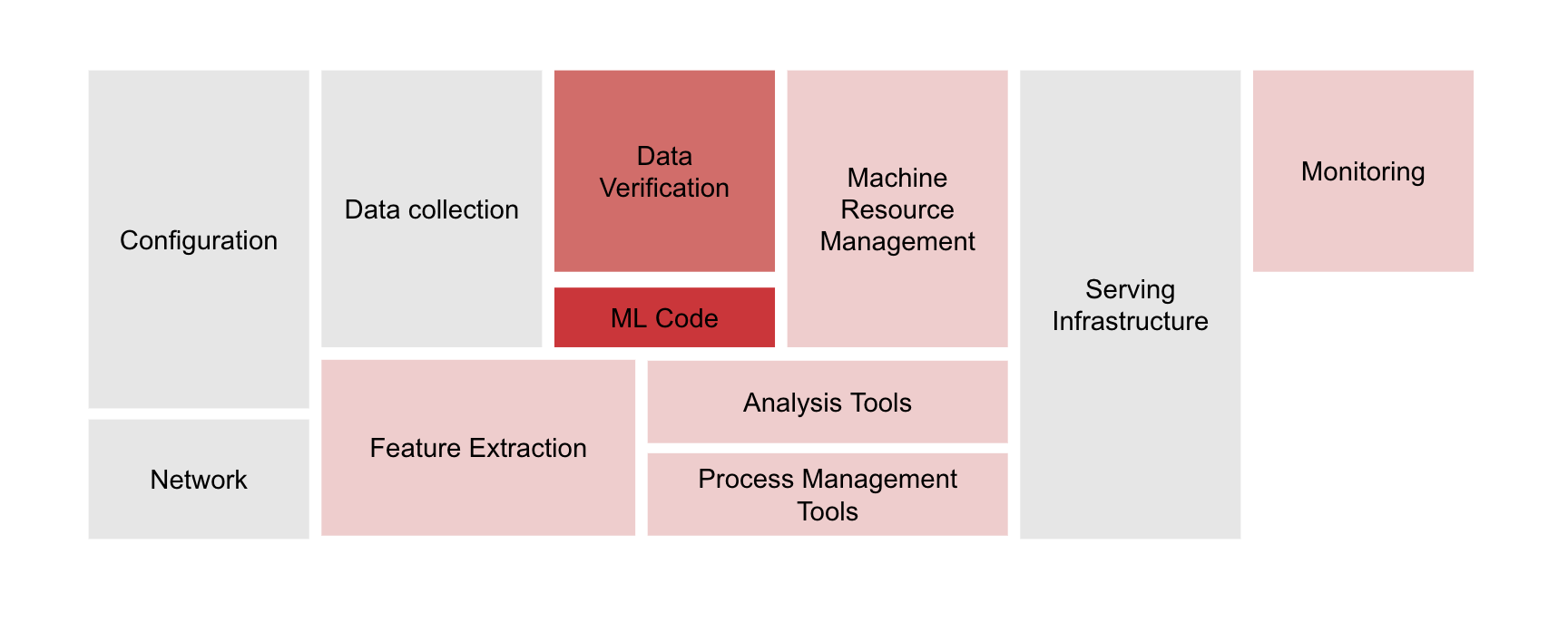
The system built around the ML code, the database, the pipelines, the APIs, the network etc. all need to be secured and built in a robust way for safe and optimal use of the model and solution. Without logging and monitoring, it is anyone’s guess if there is something untoward going on or not. Without proper guardrails it is possible, for example, to attack a generative AI system by just flooding it with requests to fill up usage and cost quotas taking the solution offline. This is called the denial of service attack.
Bringing value by selecting the role with expertise
Machine learning, including generative AI, should be used in business only when it brings actual business value in some way. This business value can be measured by improvement in KPIs or also on issues such as employee satisfaction and retention. This value should be high enough to account for the development, maintenance, and further development costs inherent in building and maintaining an ML system.
These costs should be considered throughout the ML system lifecycle as it is not something you can build and leave to fend for itself. It needs proper care and periodic training. A better way of viewing this, than just developing an AI, is adopting an AI, which makes the company doing it responsible for developing it in a way that is safe for the business and end users throughout its life cycle.
While there are many ways to ensure and bring about business value, selecting the role of the ML model use is one of the main ones. Any model is a very specific instrument for a specific use case. I like to refer to it as a scalpel. It is very good at what it does. But it is not a multipurpose tool. The problem formulation needs to be very specific. In the case of tools such as ChatGPT, this is still the case even though it can do many things. But it cannot do them in one API call. While the model can do many types of tasks, it is far safer to design the system so that each call to the API of the model only does one clearly defined thing while also giving the model guardrails to follow for safe usage.
This is the reason many ML solutions that bring true business value consist of several models or API calls. Each single one does its very specific task and jointly they do big things together.
Stay safe to bring value
While it is fine to play around with the new tools and toys, to bring value ML systems need to be safe, robust, and secure. This requires MLOps and cybersecurity best practices. It requires the ability to develop the appropriate architecture to solve the business case and fit in the client’s technology stack and expertise. It also needs the following:
- Know your data, where it has been and what has been done to it. If this is not possible, treat it with a healthy scepticism.
- Think through the architecture choices of the system carefully.
- Authenticate and authorise with the minimal access policy.
- Consider the role of AI carefully and with subject matter experts.
- Acknowledge that a GenAI foundation model has been trained with internet data and the jury is still out about if that’s allowed. Also, we all know the quality of data on the internet.
- Limit the feature of GenAI to hallucinate falsehoods by limiting its role and using your data and careful prompting.
- Acknowledge that a GenAI can be prompted to circumvent its design and safeguards and use appropriately.
- If you cannot check the facts provided by the GenAI, do not use the content.
Author

Satu Korhonen
Alumn
