Databricks Lakehouse presents itself as an open and unified platform, designed to handle all forms of organizational data. This includes structured data and unstructured data types such as logs, text, audio, video, and images. The platform’s capabilities extend to integrating the complete data and AI (Artificial Intelligence) ecosystem. This ecosystem includes various elements such as data sources, data integration, orchestration, data governance and security, business intelligence, machine learning, and AI.
In the face of the exponential growth of data in recent years, many companies and enterprises have turned to cloud-based data warehousing to adopt a data-driven approach. Traditional data warehouses, however, fall short when it comes to processing unstructured data. As a result, raw data, such as files, are initially stored in a data lake and then transferred to a cloud-based data warehouse for further processing. Databricks diverges from this approach by introducing the Data Lakehouse architecture. This innovative model combines the key advantages of both data lakes (which store large volumes of raw data in their original format) and data warehouses (which house organised sets of structured data) within a single platform. This fusion empowers companies, organisations, and enterprises to manage and utilise structured, semi-structured, and unstructured data for traditional Business Intelligence (BI) reporting as well as Machine Learning (ML) workloads.
Traditional data warehousing vs. Databricks
The shift to cloud-based data warehousing has certainly brought about scalability advantages. However, it still falls short in providing support for semi-structured or unstructured data, and the schemas remain rigid. The existence of numerous disparate systems, such as a separate data lake and data warehouse, can lead to the creation of data silos. These silos can inadvertently restrict data access for users, thereby directly impacting business intelligence and analytics solutions.
In contrast, the Databricks Data Lakehouse offers many benefits. It accommodates open storage formats and supports a wide variety of data types. The platform is designed to handle diverse workloads and offers end-to-end streaming support. The schema is simplified, making it easier to govern. The Lakehouse proves to be cost-effective due to its low-cost storage, which is decoupled from efficient compute resources. This directly influences the implementation and maintenance costs. It opens a broader range of potential use cases, as it combines data analytics and BI reporting with Data Science, Machine Learning, and real-time streaming use cases. Furthermore, it allows for easy access to data at various stages: raw data, cleansed data, or fully structured data.
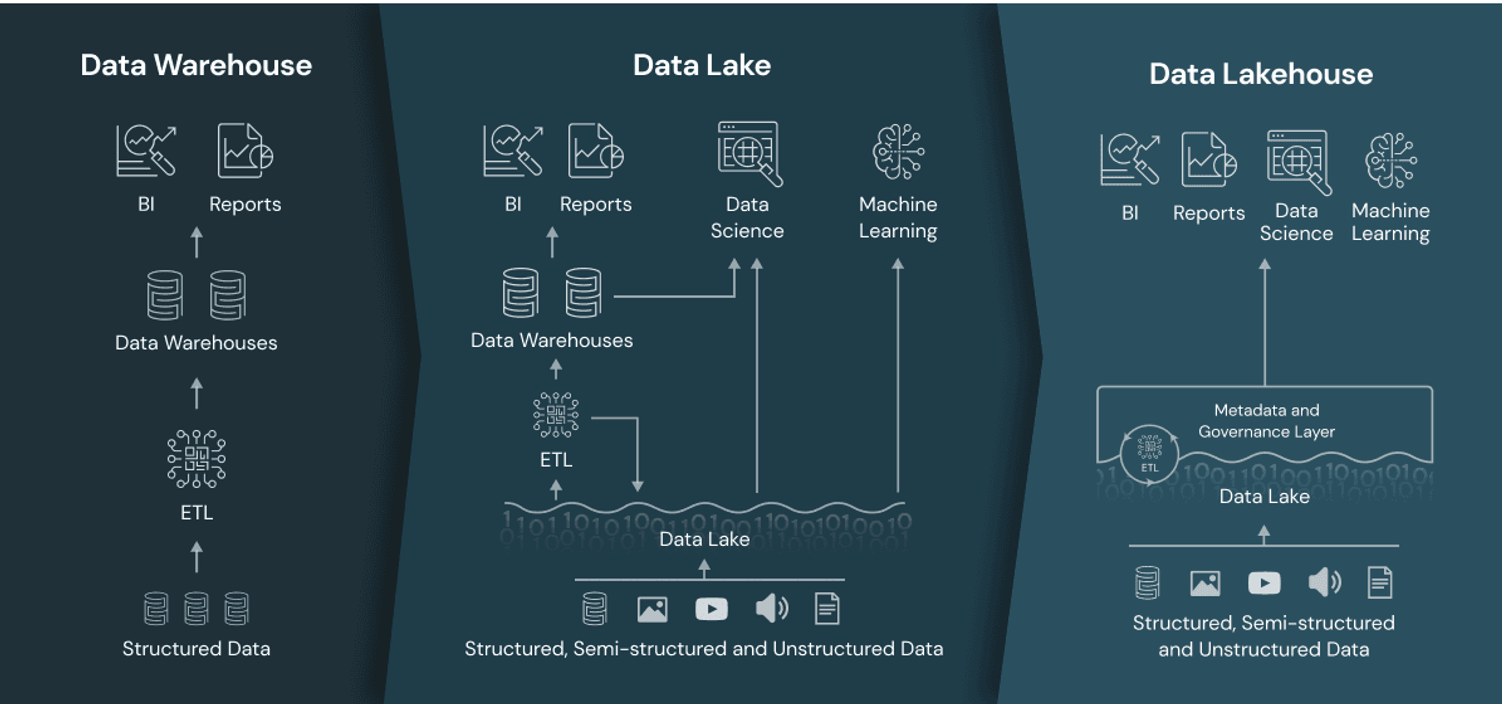
The Databricks Lakehouse architecture
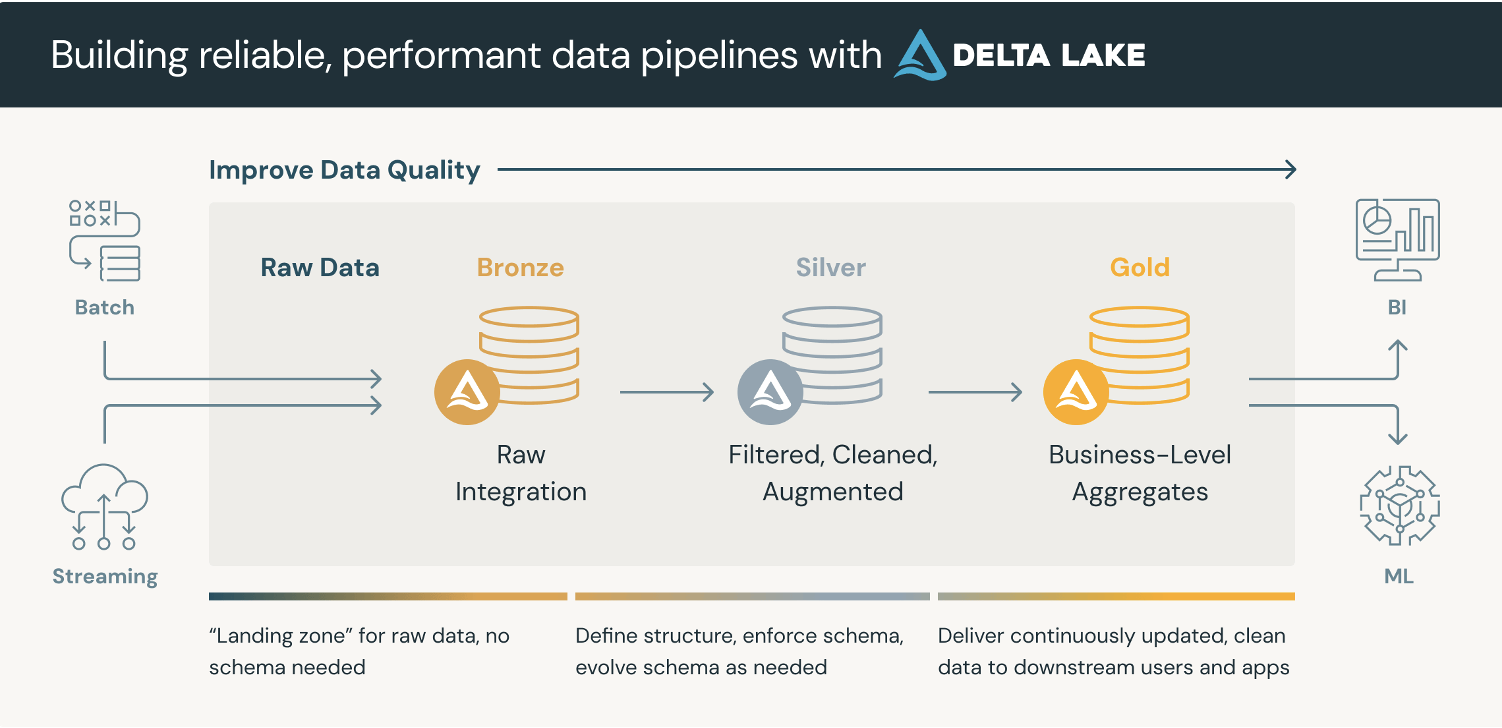
The Databricks Data Lakehouse ushers in the Medallion Architecture paradigm. Data can be ingested in either batch or stream form. The architecture comprises three distinct layers:
- The Bronze layer, housing raw data enriched with metadata that describes the ingestion process of the records.
- The Silver layer, which validates and enriches the fields, filtering, cleaning, and augmenting the data.
- The Gold layer contains aggregate data that drives business insights and dashboarding.
As data traverses through the pipeline, it is incrementally transformed and enriched. In addition to structured data, the architecture also supports semi-structured and unstructured data. It serves as a central repository, combining the capabilities of a data lake and a data warehouse. This approach mitigates the creation of data silos, as even raw data can be accessed within the platform.
Core components of Databricks Lakehouse
- Delta Lake: Serving as the cornerstone of the Lakehouse, Delta Lake is an open-source storage layer that introduces ACID (Atomicity, Consistency, Isolation, Durability) transactions to object storage data tables. It offers a reliable and high-performance solution for storing datasets of all sizes.
- Unity Catalog: This is a unified data catalog for all data assets. It provides a single, collaborative workspace for data teams to govern, discover, understand, and evolve all data assets. The Unity Catalog acts as a comprehensive system for managing data assets, serving as a central repository for all types of metadata, including tools for access control, auditing, lineage, and data governance. It is a centralised hub for administering and auditing data access.
- Photon: Photon is a state-of-the-art distributed SQL engine designed for real-time analytics and data warehousing. Built for speed and efficiency, Photon is engineered to accelerate ‘DataFrames’ and SQL workloads in a Databricks runtime environment. It achieves this by leveraging modern CPU architecture and memory hierarchy more efficiently.
- Delta Sharing: This is the industry’s first open protocol for securely sharing data across organisations in real-time, irrespective of the computing platforms they use. It enables secure and governed data sharing and is platform-independent. It is natively integrated into the Unity Catalog.
- Delta Live Tables: This feature of Databricks simplifies the process of building, deploying, and maintaining data pipelines. Delta Live Tables provides a structured framework for organising data transformations and ensuring data reliability and quality. It serves as a declarative Extract-Load-Transform (ELT) pipeline framework
Conclusion
In essence, the Databricks Lakehouse solution offers a transformative approach to data warehousing by integrating the benefits of both a data lake and a data warehouse. This fusion provides a powerful platform for managing and analysing data.
For further insights into the practical applications of this technology, we invite you to explore the projects that Solita has been involved in. One such project, which demonstrates the power of AI in blood analytics, can be found here.
If you’re interested in being part of Solita, you should check out our open positions.
Author

Olli Mämmelä
Data Engineer, Solita
