Take a peek under the hood of AI chatbots and get answers to common misconceptions.
The models that power modern chatbots are trained to imitate human text and amidst the current maelstrom of AI hype, it isn’t surprising that many misconceptions about these systems flourish. Humans tend to anthropomorphise, assigning human traits to the non-human, which is further encouraged by the way the chatbots interact with us. Throughout these last years, I’ve seen how the guise of humanlike features of modern AI chatbots often misguides users. Do you also feel the impulse to write “thank you” after receiving helpful messages from AI? I do, despite my knowledge of what goes under the hood. The illusion of a person at the other end of the chat, upheld actively by design choices such as having the model refer to itself as “I”, can be conceptually convenient at times, but might also lead one to wrongfully assume it has certain abilities that are reasonable to expect from a mind that seems to resemble our own.
Learning some basics about how these systems work can be very useful, making it easier to avoid common misconceptions and to find the right use cases for this technology. My intention with this post is to provide an introduction for readers who are curious about the inner workings of modern chatbots and to help dispel misconceptions and navigate the current hype.
The intelligence at the core
At the heart of modern chatbots is the model, which can be understood as an extensive set of instructions for a computer on how to perform a specific calculation. This calculation takes any text as input and calculates a list that estimates the probability of every possible word to come next in the text. You can imagine handing a piece of paper with text to the model, and it hands you back a dictionary with an estimated probability scribbled next to each word. technically speaking, it is a dictionary of all possible tokens, which can be full words, parts of words or other things such as punctuation, symbols, emojis or line breaks.
Once the list of probabilities has been returned, the calculation is finished. To generate a longer text, the next word is randomly drawn according to the estimated probabilities and added to the original input text, and the calculation is run again. This is repeated, adding one word at a time.
Image: The model is applied inside a loop in order to generate longer texts. Each estimate relies only on the input, so one might as well consider that the model is “replaced” after each estimation.
The specific type of model used in modern chatbots is a kind of artificial neural network (ANN) called a transformer. They are also often referred to as large language models or LLM:s when used in this context. Technically speaking, an LLM can be any kind of large ANN used for language generation, but all modern systems currently use transformers. As the term artificial neural network implies, these models are inspired by the natural neural networks we animals carry around in our heads.
Transformers “learn from data”. As part of its instructions on how to calculate next word probabilities, it uses a vast number of values called parameters. These values are first calculated using enormous datasets of text during a process called training. The training involves different steps, some that are pure algorithms and others that may involve humans giving feedback. The important detail for us to remember is that the training happens first and is separate from when the model is later used to generate text.
The model is the core “intelligence” which gives rise to the astounding capabilities modern chatbots have. The model is one subsystem of many in a larger chatbot system, but it is what makes a modern chatbot different from “regular” software. The model puts the AI in genAI, so to speak.
The chat format
When these models are used in modern chatbots, part of the training has included learning adherence to the chat format. During a stage often referred to as fine-tuning, the model is trained specifically on examples of replies to questions in a chat-style conversation. At the end of each message, a special “message end” character is added, effectively teaching the model to signal when its response is finished by predicting this character. During inference (when the model is used to produce text to send back as an answer to a user), whenever the generated token is this “message end” character, the text generation loop pauses. The generated output text is sent as a message to the user, and the system is dormant until the user writes something in response. Without this break of the loop, the model would likely go on to try to predict the user’s response, as that is the most probable thing to happen after the “message end” character in a message from the model.
Nothing in the model itself changes as you interact with it. The chatbot, as stated before, includes several other subsystems that might store old conversations and change state in various ways as you interact with it, as any computer program with memory and states can do. This, in turn, changes what is included in the input text to the model behind the scenes. Memory is handled by “regular” code. The model, as always, is only calculating next-word probabilities from an input text.
No continuous mind
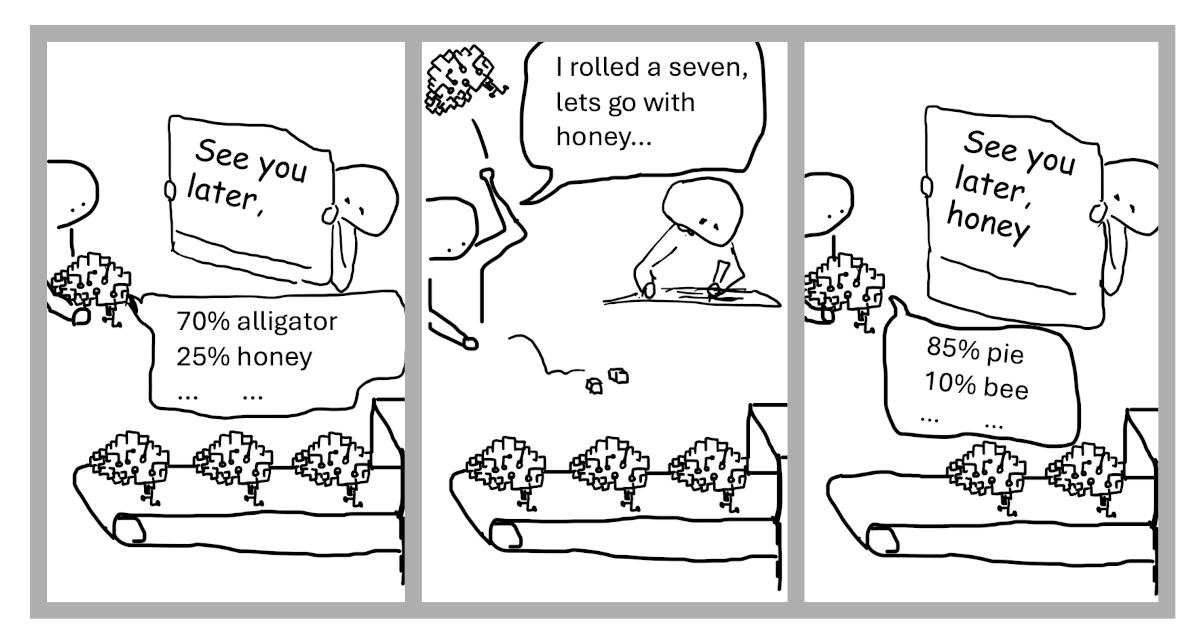
Considering the structure described above, a few things might become apparent. The model isn’t somehow aware that a longer text is being written at all. The only thing that changes from a previous iteration to the next iteration is the input text. The idea that these systems are somehow continuous individuals is a prime example of the anthropomorphising I mentioned earlier. The internal processes of the model are entirely dependent on the developing text message. This is a practical difference between human brains and current GenAI models. The neural activity in your brain doesn’t only rely on the input from your senses, but also on the internal state of your brain just a moment ago. Neurons in the human brain connect in loops. In a transformer, once the calculation has run, the virtual neurons of the model conceptually cease to exist, and when run again, the output is always solely determined by the input text.
Reasoning and agentic AI
As simple as “a calculation is run” sounds, something truly remarkable happens in these models, as evidenced by the stunning abilities they give modern chatbots, ranging from complex coding to writing scholarly essays. If you’ve come across the term emergence in relation to AI, this is exactly it: while optimising for next word prediction, these models have apparently learned a capacity for complex thought. However, this “thought” works very differently from our own, without any continuous consciousness.
The fact that the performance improves on many tasks if the model is instructed to first write down what it is “thinking” might strengthen the illusion of some continuous individual behind the text. This is often referred to as “giving access to reasoning” or “chain of thought”. Such models go through additional training phases that optimise their parameters not just for next word prediction but also for using the reasoning “scratch pad” and solving problems. This adjusts the model parameters, but the model still calculates next word probabilities from an input text.
By putting LLMs at the steering wheel of more advanced systems, we get what is referred to as agents. These can carry out advanced tasks autonomously, which is achieved through extensive input texts and smart code wrappers that let the model interface with other systems, “giving the model access to tools”. At the core, the model is chugging away as before, one word at a time, no memories stored between words aside from what is explicitly added to the input text. It is as oblivious as ever to the fact that a longer text is being written or that external software is being triggered.
Image: The “illusion” of chatbots being persistent individuals is actively enforced by fine-tuning the models to chat format interactions, including referring to itself as ” I”.
Misconceptions
Let me address how this directly dispels some misconceptions I’ve met often in the last couple of years. Recurringly I see the expectation that a chatbot could answer questions about its own capabilities based on its own “experiences”. As we’ve seen, it has no experience of itself. It will answer whatever descriptions seem most reasonable, given the model’s training data and input prompt. Generally, this gives correct statements, but I’ve also seen stakeholders receive hallucinated answers that they’ve intuitively trusted since the chatbot was “talking about itself”.
On the same theme, a common expectation is that a chatbot will “learn” over time from user interactions. Whether this is a reasonable expectation or not depends on which chatbot you use. The models aren’t capable of continuous learning through interactions, any memory is handled by other subsystems and fed to the model through the input text. Additionally, providers of the chatbot might use previous chats as training data for new iterations of the model, but this requires retraining to adjust model parameters. Inference and training are two distinctly separate processes.
This ties into another misconception I’ve often met, the idea that you are somehow interacting with the same “entity” as someone else who is using the same chatbot. It is only the same entity in the sense that the same parameter values are used in the calculation, but there are no other connections.
Is that so different from a human?
We also pick the next word based on learned language patterns and our speech center is separate from other “subsystems” of the brain. There may or may not be similarities between transformers and how we reflexively generate single words as we speak, but zoom out a little and we see that the transformer is a process without any intention, only giving rise to a text because of the wrapping code loop of repeatedly picking the next word from its output and feeding the resulting text back in.
This is a stark difference to our human brains, where functions such as language generation are apparently deeply integrated with such strange persistent neural states as goals, ideas, personality and whatever else might influence what we choose to say. These things in turn are dynamic qualities that change as we learn from experience. An inspiring conversation might leave our neural networks permanently changed, affecting both future intent and language capabilities, greatly affecting what words we choose in certain situation from that point onwards. Try as you may, however inspiring innovating commentary you provide a modern chatbot with, neither the model parameters that govern its output nor the code running the inference loop will change in response.
Can we be entirely sure there is nothing sentient in these machines? Getting philosophical, perhaps one could imagine a flash of some kind of consciousness when the virtual neurons fire during inference, a split second of conceptual thought, ever so brief, as the next word probabilities are calculated. But a moment later, all activity is gone, the virtual neurons conceptually cease existing, any thoughts or experiences lost (like tears in rain, one feels inclined to add). As the process loops, a new consciousness might flash, calculating the next word probabilities of the slightly altered text, with no connection to its predecessor except the word that was randomly drawn from the predecessor’s output.
The lie of the “I”
When your laptop battery is running low, the warning doesn’t state “my batteries are running low”. The models inside chatbots have been fine-tuned to refer to themselves in the first person. I’ll steal a joke I read recently: Put a paper with the words “I think therefore I am” into a photocopier, and you can have it to profess its existence as an individual with the press of a button.
By reminding ourselves that these are probability estimation algorithms wrapped in looping code, we find a good starting point for our intuition of these systems. The abilities of modern AI are breathtaking, yet behind the mimicry of human behaviour, as we pull back the curtain, we find only the ticking clockwork of an algorithm, no persistent mind. The house may be impressive, but make no mistake, there is no one home.
Want to check out our open positions or read more about AI? And if you want to discuss AI opportunities, contact us!
Thanks to my colleagues Lauri Keksi, Ari Rahikkala and Tommy Jensen for proofreading and suggestions.