The Snowflake World Tour came to Stockholm this October, offering a full day of insightful presentations from Snowflake, their customers, and partners. We recently renewed the highest-level Snowflake Elite Partner status, as well as being honoured with two awards at Snowflake Partner Awards the evening prior, and of course, took part as an exhibitor. I was fortunate enough to visit the conference. With four simultaneous presentations throughout seven breakout sessions, it was impossible to cover everything. My goal was to learn as much as possible about how companies are adopting data mesh with Snowflake’s help.
Decentralisation is a term that might linger with you after hearing about this sociotechnical framework, as one of its principles emphasises that business domains should own the data they produce and consume. Looking for data mesh insights at a single-vendor conference for something as historically centralised as a data warehouse might seem surprising. But Snowflake’s platform unifies rather than centralises; however, I was surprised that more than half of the sessions included a presentation on data mesh!
What is data mesh?
Let’s explore what data mesh is before digging into the takeaways from the presentations. The concept was introduced by Zhamak Dehghani in 2019 with the blog post How to move beyond a monolithic data lake to a distributed data mesh, later thoroughly formalised in the 2022 book on delivering data-driven value at scale. There it’s classified as a sociotechnical paradigm with four interrelating principles at its core.
Principle of domain ownership
Domain-driven data ownership makes the domains responsible for the correctness of the data they produce. The transformation needed for curated data, the data pipeline, is moved into the domain. This way, the data is aligned to its source while also readily available for potential aggregation and cross-domain use.
Principle of data as a product
To increase the usability of the domain data and mitigate the silo effect that could come with decentralisation, product thinking is applied to the modelling and sharing of data. The concept of data products is what’s most prominent coming out of the principles, and there are several standardisation efforts ongoing, e.g. Open Data Product Standard (OPDS) by bitol and Data Product Ontology (DPROD) by EKGF. Dehghani laid out eight characteristics as the baseline for a data product to be considered useful, namely
- Discoverable: Easily explorable by data users
- Addressable: Has a distinct identifier serving as entry to all associated information, including documentation and service-level objectives
- Understandable: Clearly communicates the entities it encapsulates, their relationships, and adjacent data products
- Trustworthy and truthful: Bridges the gap between users’ known and unknown aspects to foster trust in the data’s reliability
- Natively accessible: Enables various data users to access and read its data using their preferred access methods
- Interoperable: Follows standards and harmonisation rules for seamless cross-domain data linking
- Valuable on its own: Contains a dataset that holds intrinsic value independently and offers inherent business and customer value
- Secure: Ensures secure access with confidentiality-preserving measures
Principle of the self-serve data platform
The self-serve platform hosts domain-agnostic infrastructure capabilities built and maintained by a platform team. Existing technologies can be leveraged to provide capabilities with data mesh differentiating characteristics.
- Serving autonomous domain-oriented teams: The platform must allow teams within the domain to build, share and use data products autonomously in an end-to-end fashion while not being dependent on centralised data teams.
- Managing autonomous and interoperable data products: The data products coming out of the domain must also be autonomous, upholding data product characteristics while being able to interconnect with other data products in the mesh without intermediate centralised assistance.
- A continuous platform of operational and analytical capabilities: Domain ownership requires a platform enabling autonomous teams to manage data end-to-end, bridging operational and analytical planes. A data mesh platform must deliver a connected user experience for both application development and data product usage.
- Designed for a generalist majority: Adopt open conventions for tech interoperability, empowering generalists with accessible tools to drive scalable data initiatives.
- Favouring decentralised technologies: Data mesh emphasises decentralisation via domain ownership to prevent synchronization bottlenecks and accelerate change. An effective self-serve platform balances centralised resource management with independent team autonomy for end-to-end data sharing, control, and governance.
- Domain agnostic: Traditionally, there’s often no clear delineation between the team preparing data for analytical use and the maintenance of the infrastructure that supports it. The self-serve platform should balance domain-agnostic capabilities while enabling capabilities not needed by all domains.
Principle of federated computational governance
For data mesh to function as an ecosystem, domains must adhere to global standards and policies despite retaining their autonomy. Key components for achieving federated computational governance are system thinking and computational policies combined with a federated operating model. A cross-functional team composed of domain data product owners and representatives from various organisational parts, such as legal, compliance, security, and platform, sets guiding values from which global policies are derived. These policies are implemented via the self-serve platform to enable both interoperability between and governance of data products.
Data mesh on Snowflake case studies
Since the principles are intertwined, we’ll consider them collectively rather than separately as we examine how some of Snowflake’s customers have adopted data mesh (i.e. the ones who presented on the topic at Snowflake World Tour Stockholm). We’ll provide an overview rather than detailing individual efforts.
All companies that presented on data mesh have shifted to empowering domains to take data ownership and integrate Snowflake into their self-serve platforms. The domains enjoy varying degrees of autonomy, scaling up and down as needed, bridging operational and analytical planes, and receiving assistance from the platform team when required competencies are missing. In one instance, a central team created group-wide data products alongside the domains; however, this role will diminish as domain competencies grow.
Resource provisioning in the data platform, such as schemas and databases, is managed via configuration files in YAML format, enabling multiple companies to abstract away the infrastructure aspect of their self-serve platform.
Several presenters emphasized considering source-aligned data products as in-domain master data. All companies made their data products discoverable through catalogues, either through third-party alternatives or Snowflake’s Internal Marketplace and Direct Sharing. Consumer-aligned and aggregated data products were also published, with the understanding that they can build upon each other for new possibilities.
Upon publication, data products are considered contextual, with producers and consumers on equal footing regarding expectations. Centralised compliance and best practices are enforced within domains through a shared information model. As the mesh grows, opportunities for cross-domain analysis will increase, overcoming silos. Interoperability between both data products and domains is crucial, with the agentic mesh’s prominence highlighting the importance of understanding data contracts.
To make data products discoverable and explore the mesh (i.e., what products derive from a given source table), object tagging in Snowflake can be leveraged. Tags enable cross-domain lineage tracking to prevent duplication of data products and aid governance by keeping track of policy relevance and enforcing legal obligations.
Snowflake services that help knit the mesh
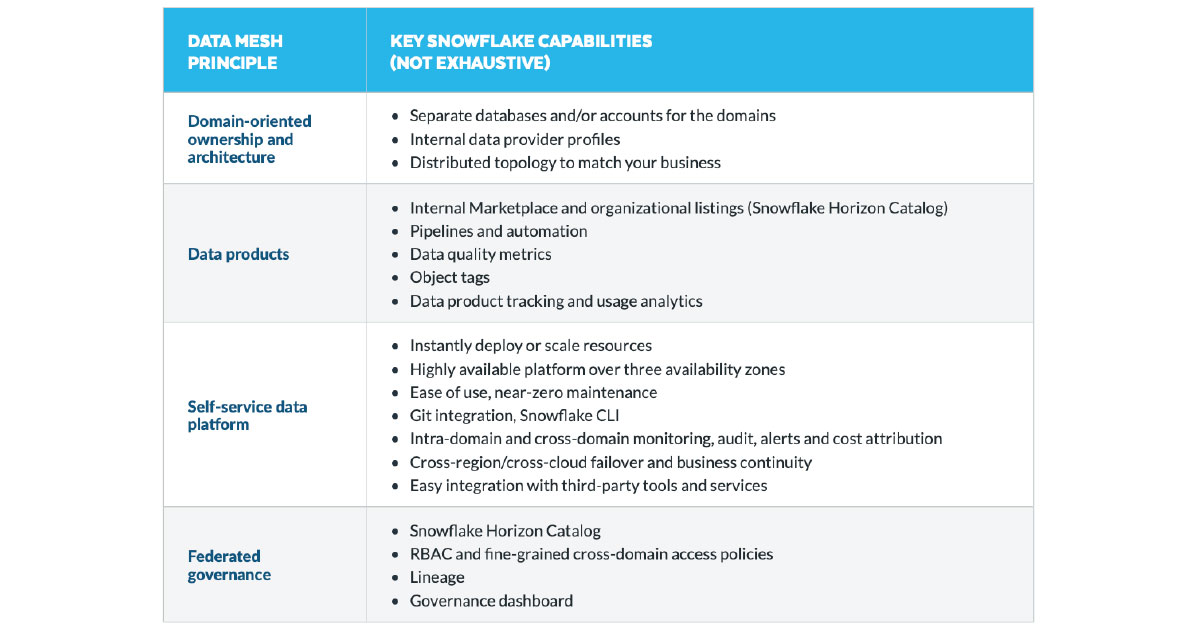
In the intersection of the presentations and the whitepaper on How to knit your data mesh on Snowflake we find multiple Snowflake capabilities to elaborate on. While previously mentioned resources have been tech-agnostic and material from Snowflake mainly focuses on what technical and architectural support their platform provides, it also does a good job sorting out the principles of data mesh.
Organisational topology
Using Snowflake to abstract away infrastructure provisioning was successfully achieved in more than one case. Solely using the platform for this might, however, result in building services already provided by Snowflake. Whether you build or buy, from either Snowflake or a third party, with proper federation of governance, it’s possible to have an interconnected mesh either way. Organising into data mesh domains in Snowflake can be achieved either at the account-level or more granularly as databases or schemas; the latter seemed to be most popularly used by presenting companies. The chosen level for domains in the platform architecture may very well depend on how the company is organised. As often discussed in data mesh discourse and reiterated in the whitepaper, Conway’s law states:
Organisations which design systems are constrained to produce designs which are copies of the communication structures of these organisations.
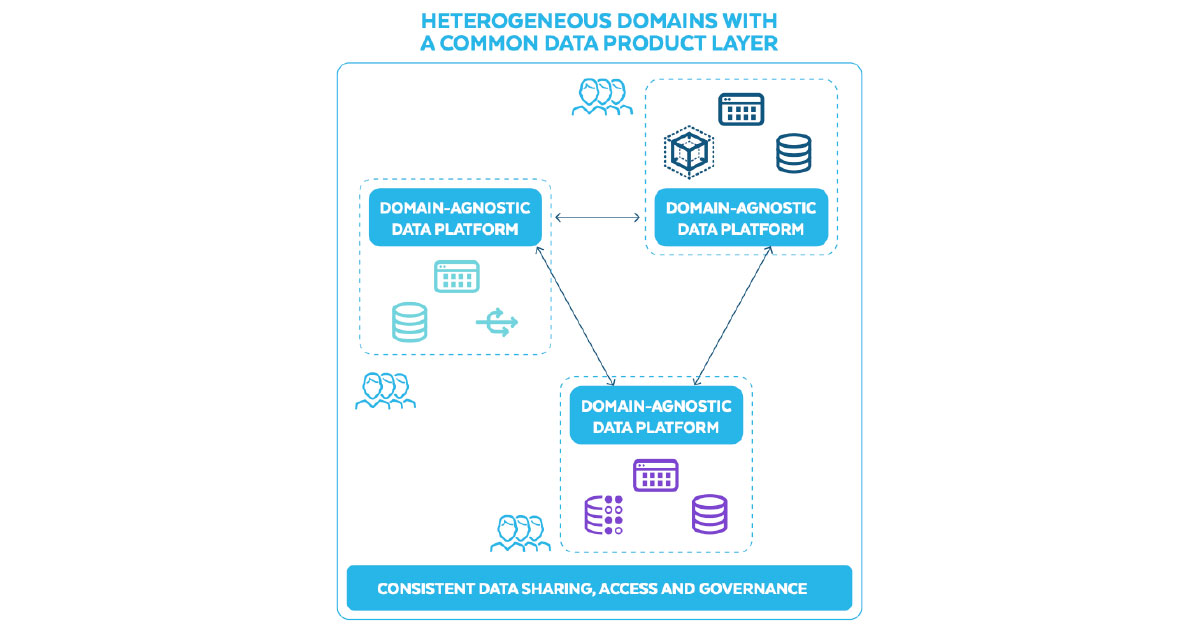
Acknowledging this fact, it is crucial to ensure that both domains and data products are interoperable across the mesh and to avoid creating organisational silos. Snowflake recommends a common data product layer for harmonisation when sharing data products across a mesh of heterogeneous technologies. Not all data from other systems and technologies needs to be replicated into Snowflake, but enough must be replicated in order for the self-serve platform of the ecosystem to maintain consistent governance, access control, and cross-domain interoperability.