RAG (Retrieval Augmented Generation) systems are more than just a 2024 buzzword as they keep gaining popularity in real-world applications. Because of this, it is now time to delve into the intricacies behind this technology and gain an understanding of the challenges and pitfalls in the engineering process. Let us therefore explore seven potential failure points to hopefully result in smoother development in the future.
TLDR
- Set similarity thresholds when retrieving to avoid hallucinations.
- Optimise retrieved document count (k) and consider filtering techniques if k is large (e.g. corrective retrieval augmented generation).
- Implement post-retrieval document processing to ensure the most suitable and clear answers.
- Ensure that the answers format matches the expectations and the specified format.
- Address noise and contradictory/conflicting information in documents (e.g. by document post-processing or CRAG-systems).
- Fully understand the question and prompt LLMs for specific output to ensure answer specificity.
- Chunk the question into several prompts, if possible, to ensure completeness so the LLM does not miss information.
- Chunking approaches (heuristic vs. keyword vs. hybrid, etc.) and alternative RAG architectures such as for instance CRAG should be made.
- Sharing is caring: open communication and knowledge sharing promote RAG development advances.
Remember struggling with LLMs’ (Large Language Models) factual inaccuracies or limited domain knowledge? RAG systems offer a solution but building them comes with its own hurdles.
Since their introduction in 2020 by Meta as a tool for addressing LLM’s common shortcomings like hallucinations and lack of real-world grounding, RAG systems have gained traction within the industry. However, despite its widespread use, there hasn’t yet been a lot of comprehensive research on the best practices and potential pitfalls when engineering these types of systems.
This blog dives into seven key failure points and pitfalls that you need to consider and avoid when developing RAG systems. This will, if dealt with, not only make life easier for the developer but ultimately provide a better experience for the customer in the end.
Let’s explore what LLMs are, how RAG systems work, and the key pitfalls to avoid for successful development.
LLMs and RAGs: A power couple solving LLM challenges
Understanding LLMs: Capabilities and constraints
While the origins of LLMs date back to the 60s with the introduction of Eliza, the world’s first chatbot, their true impact is felt today. Here, LLMs like ChatGPT and Gemini leverage vast amounts of data for model training and state-of-the-art AI techniques such as transformers and the idea of self-attention, advanced deep learning techniques, as well as conventional unsupervised and supervised machine learning techniques. These techniques combined enable the LLMs to summarise, translate, analyse, and even converse naturally with a human agent, but also so much more.
It is easy to imagine the marvels of these modern AI capabilities, but what if they sometimes get carried away, by for instance inventing facts that have never existed? These tools can still be susceptible to limitations, and some of the most known hereof are:
- Hallucinated responses: Fabricates incorrect answers despite correct logic and syntax
- Lack of references: Cannot subsidise its claims with references
- Limited knowledge: Responds only based on training data, and not real-time updates or domain expertise
- Unbounded: Difficulties to guide, direct and/or update LLMs generated output text
No more fake news: Introducing RAG systems
To approach these limitations, in enters RAG systems, the potential missing piece in the LLM puzzle. These systems leverage the LLMs for answer generation with one significant improvement. By incorporating real-world and domain-specific information extracted from pre-indexed documents other than what the LLM was originally trained on, RAG systems provide the context and knowledge that LLMs often lack. Think of it as a library with verified information of which the LLM can base its responses on. This way, RAG systems create a dynamic duo that addresses LLM shortcomings by delivering more accurate and grounded responses.
The magic of RAG systems lies in its two-step process: indexing and querying.
Indexing (See Figure 1): Imagine chopping up relevant documents (e.g. articles, product descriptions, legal documents, presentation transcripts, etc.) into smaller, meaningful chunks. Each of these meaningful chunks are then associated with a numerical representation of its content in the form of embeddings (a vector of numerical values). These associations are then stored in a vector database which provides the opportunity to later retrieve the chunks of text and their embedding representation.
Querying (See Figure 1): After indexing all the document chunks, the RAG system aims to answer questions (queries) from natural language inputs by utilising the knowledge stored in the database. When a question is being asked, the RAG system will start by considering whether the query should be rewritten to a more suitable format or not, by using an LLM. Then, like when indexing, the query is represented as an embedding. The RAG system will then search through the database comparing the query with the stored chunks, by measuring their similarity (e.g. by cosine similarity). The top-k most similar chunks are then retrieved and potentially re-ranked to maximise the likelihood of a chunk containing the answer to the query. Now, the LLM is provided with the query as well as the similar chunks, providing the LLM with valuable context and up-to-date knowledge to understand the intent, and from this generate an accurate, grounded, and informed response.
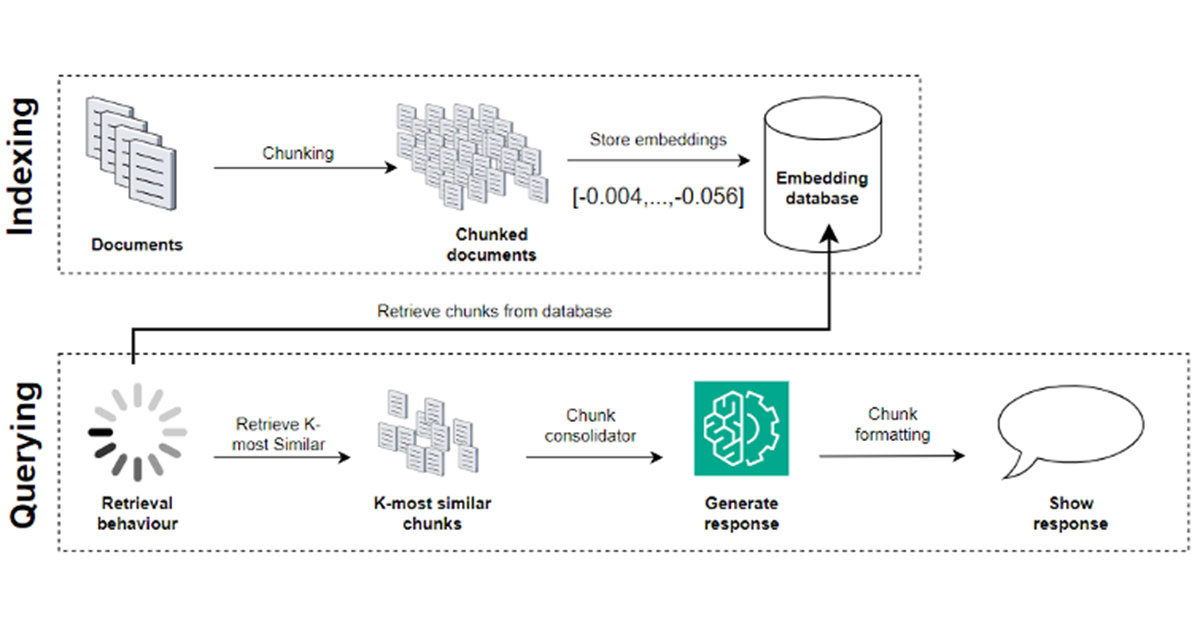
Figure 1: Retrieval Augmented Generation system overview
There you have it, LLM superheroes. But while RAG systems grasp the “wow” factor, the development and engineering of it hold important complexities that should be addressed.
Whoops! Did your RAG system just fail? 7 pitfalls and mitigations when engineering
We have now discussed LLMs and RAG. Now, imagine building a powerful RAG system, only to discover that it struggles when tackling the real world. The road to building a successful RAG system is not without bumps and scratches. Therefore, let’s dive into the seven failure points (See Table 1) identified by the work of Barnett Et. Al. (2024) and explore the strategies to overcome these.
1. Missing content
Description: The database doesn’t contain chunks that can be used as context to answer the query.
Possible mitigation: A low similarity threshold could be implemented. Trigger an honest “I don’t know” when information is lacking, instead of hallucinating. Find and add relevant chunks that were not in the database before. Clean your data and improve prompting to utilise the data in the best way possible.
2. Missed top-ranked documents
Description: The answer might be in the database, but the chunk didn’t rank as one of the top-k retrieved chunks.
Possible mitigation: Fine-tune the retrieval process to retrieve optimal hyperparameters. Consider using corrective retrieval augmented generation for chunk filtering out ambiguous or incorrect chunks if the number is too high. Add metadata, e.g. dates and purposes, to chunks in the database, to easier filter the most relevant chunks. Investigate chunking strategies that fit your purpose and utilise the LLM token limit. Excessively large or excessively small chunks might lead to retrieval issues. Consider utilising a hybrid search, combining both keyword and context, as a measure for document retrieval. Consider using reranking techniques for the documents/chunks.
3. Not in context
Description: Chunks containing the answer is retrieved, but the information got lost in translation and didn’t make it into the output (the context isn’t shown in the answer after e.g. reranking).
Possible mitigation: Too many chunks were retrieved, and the system consolidates the most important parts. Post-processing of the retrieved chunks is necessary before feeding them into the LLM as context, for instance by (e.g. diversity ranker) re-ranking. Use smaller LLMs to search for mutual information across chunks and summarise this in one concise context. Tweak retrieval strategies and finetune embeddings.
4. Wrong format
Description: The LLM fails to extract the information in the format specified in the prompt (e.g. table, json, list, etc.).
Possible mitigation: Be more specific/clarify instructions in the prompt to ensure the importance of the format. Generally, utilise better prompting techniques. Give examples of how you would like the output to be. Prompt iteratively (trial-and-error) to eventually show the right format. Use e.g. LangChain output parser.
5. Not extracted
Description: The answer might be in the retrieved chunks, but the LLM fails to extract the correct information.
Possible mitigation: Result from noise or contradictory information in the retrieved chunks. Use noise reduction techniques to ensure consistent information.
6. Incorrect specificity
Description: The answer is technically correct, but it lacks detail and specificity.
Possible mitigation: Prompt the LLM to increase specificity, and how. Fully understand your question to ensure that it doesn’t become too general. Utilise more advanced retrieval strategies (e.g. recursive retrieval).
7. Incompleteness
Description: The answer to your question feels incomplete, as it only partially answered it or missed some information.
Possible mitigation: Divide and conquer by breaking complex questions into smaller, more manageable ones to utilise the RAG capabilities. Reformulate the question at hand.
Other potential failure points are worth mentioning, for instance when having an ingestion pipeline, you should make sure that it scales well for processing larger amounts of data. We will however stay with the above-mentioned pitfalls for this blogpost.
To get a better intuition as to where in the RAG pipeline each of the failure points arises, see Figure 2.
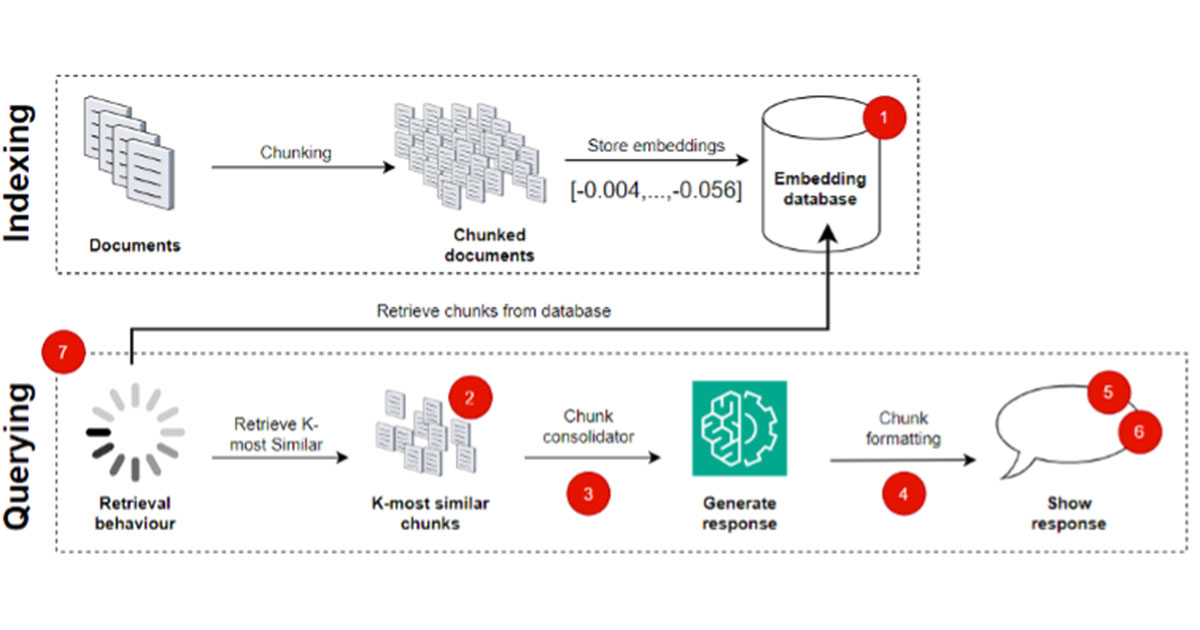
Figure 2: Retrieval Augmented Generation system overview, with failure points
Finetuning: Utilising RAGs full potential
While we now have a deeper understanding and intuition of failure points and considerations in the development process, new questions remain. Specifically, one of these is with respect to the chunking size of the documents. Here, we need to explore whether a data-driven, keyword-based approach to chunking holds the most promise, or if a more sophisticated, semantic approach would be more effective. Additionally, there is also the consideration of a more hybrid solution between the two is feasible.
Further, remember the clever CRAG system mentioned earlier? Its ability to deal with incorrect or ambiguous chunks retrieved could be a valuable tool in the question for even more accurate answers and therefore should be explored even further.
This however is just the beginning. Therefore, let’s continue working together, sharing insights, and pushing the boundaries of RAG development. Who knows, what exciting applications and discoveries of the technique await around the next bend.
Final remarks: Beyond the hype, building a brighter RAG future
The RAG architecture has taken the stage in LLM applications, with its popularity rising at unmatched speeds. Yet, as explored in this blog post, potential limitations and pitfalls still lurk, such as missing content, hidden answers, format mishaps, and more.
It is about building better systems, for developers and users. By understanding these seven failure points (missing content, missed top-k chunks, not in context, not extracted, wrong format, incorrect specificity, and incompleteness), we can create smoother and more empowering experiences.
Keep in mind though, that this is just the opening chapter of the RAG era, and what has been proposed in this blogpost is only the presumably most important. Vast areas of research are waiting to be explored, and by sharing our findings, collaborating, and continuously refining our understanding, we can push the boundaries of RAG systems in 2024 and beyond.
References: Barnett, S., Kurniawan, S., Thudumu, S., Brannelly, Z., & Abdelrazek, M. (2024). Seven Failure Points When Engineering a Retrieval Augmented Generation System. arXiv preprint arXiv:2401.05856.
Author

Magnus Lindberg Christensen
Alumn
