The linked code repository contains a minimal setup to automatize infrastructure and code deployment simultaneously from Azure DevOps Git Repositories to Databricks.
TL;DR
- Import the repo into a fresh Azure DevOps project
- Get a secret access token from your Databricks workspace
- Paste the token and the Databricks URL into an Azure DevOps library’s variable group named “databricks_cli”
- Create and run two pipelines referencing the YAML in the repo’s pipelines/directory
- Any Databricks compatible (Python, Scala, R) code pushed to the remote repository’s workspace/directory will be copied to the Databricks workspace with an interactive cluster waiting to execute it
Background
Azure DevOps and Databricks have one thing in common – providing industry standard technology and offering them as an intuitive, managed platform:
- Databricks for running Apache Spark
- DevOps for Git repos and build pipelines
Both platforms have much more to offer then what is used in this minimal integration example. DevOps offers wiki, bug-, task- and issue tracking, canban, scrum and workflow functionality among others.
Databricks is a fully managed and optimized Apache Spark PaaS. It can natively execute Scala, Python, PySpark, R, SparkR, SQL and Bash code; some cluster types have Tensorflow installed and configured (inclusive GPU drivers). Integration of the H2O machine learning platform is quite straight forward. In essence Databricks is a highly performant general purpose data science and engineering platform which tackles virtually any challenge in the Big Data universe.
Both have free tiers and a pay-as-you-go pricing model.
Databricks provides infrastructure as code. A few lines of JSON consistently deploy an optimized Apache Spark runtime.
After several projects and the increasing need to build and prototype in a managed and reproducible way the DevOps-Databricks combination became very appreciated: It enables quick and responsive interactive runtimes and provides best industry practice for software development and data engineering. Deployment into (scheduled), performant, resilient production environments is possible without changes to the platform and without any need for refactoring.
The core of the integration uses Databricks infrastructure-as-code (IaC) capability together with DevOps pipelines functionality to deploy any kind of code.
- The Databricks CLI facilitates programmatic access to Databricks and
- The managed Build Agents in DevOps deploy both infrastructure and analytic code.
Azure pipelines deploy both the infrastructure code and the notebook code from the repository to the Databricks workspace. This enables version control of both the runtime and the code in one compact, responsive repository.
All pieces of the integration are hosted in a single, compact repository which make all parts of a data and modeling pipeline fully reproducible.
Prerequisites
Log into Azure DevOps and Databricks Workspace. There are free tiers for both of them. Setup details are explained extensively in the canonical quick start sections of either service:
For the integration Databricks can be hosted in either the Azure or AWS cloud.
1. Import the repository
To use this demo as a starting point for a new project, prepare a Azure DevOps project:
create a new project (with an empty repository by default)
select the repository tab and choose “Import a repository”
paste the URL of this demo into the Clone URL field: https://dev.azure.com/reinhardseifert/DatabricksDevOps/_git/DatabricksDevOps
wait for the import to complete
clone the newly imported repository to your local computer to start deploying your own code into the workspace directory
Then create two Azure pipelines which create the runtime and sync any code updates into it (see below).
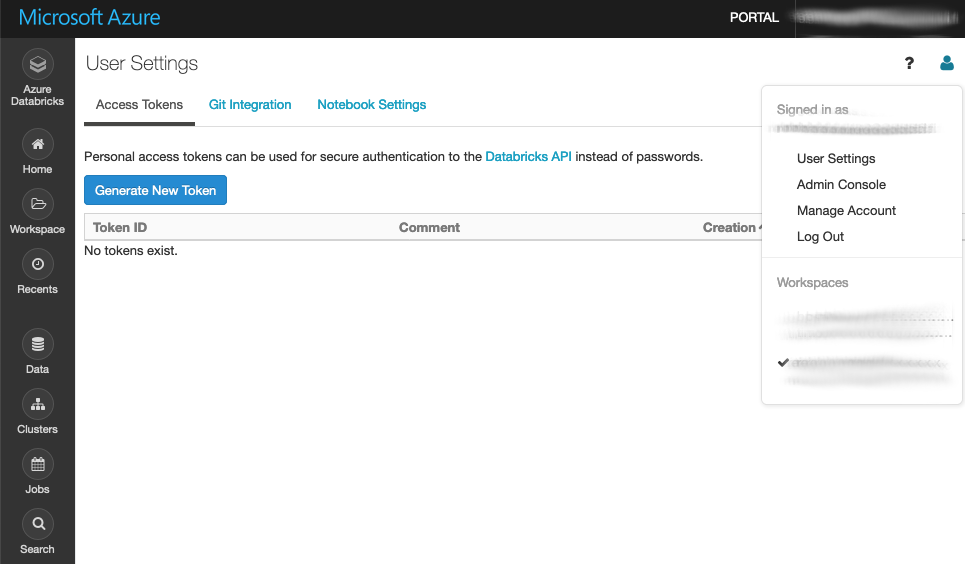
2. Create Databricks secret token
Log into the Databricks workspace and under User settings (icon in the top right corner) and select “Generate new token”. Choose a descriptive name (“DevOps Build Agent Key”) and copy the token to a notebook or clipboard. The token is displayed just once – directly after creation, you can create as many tokens as you wish.
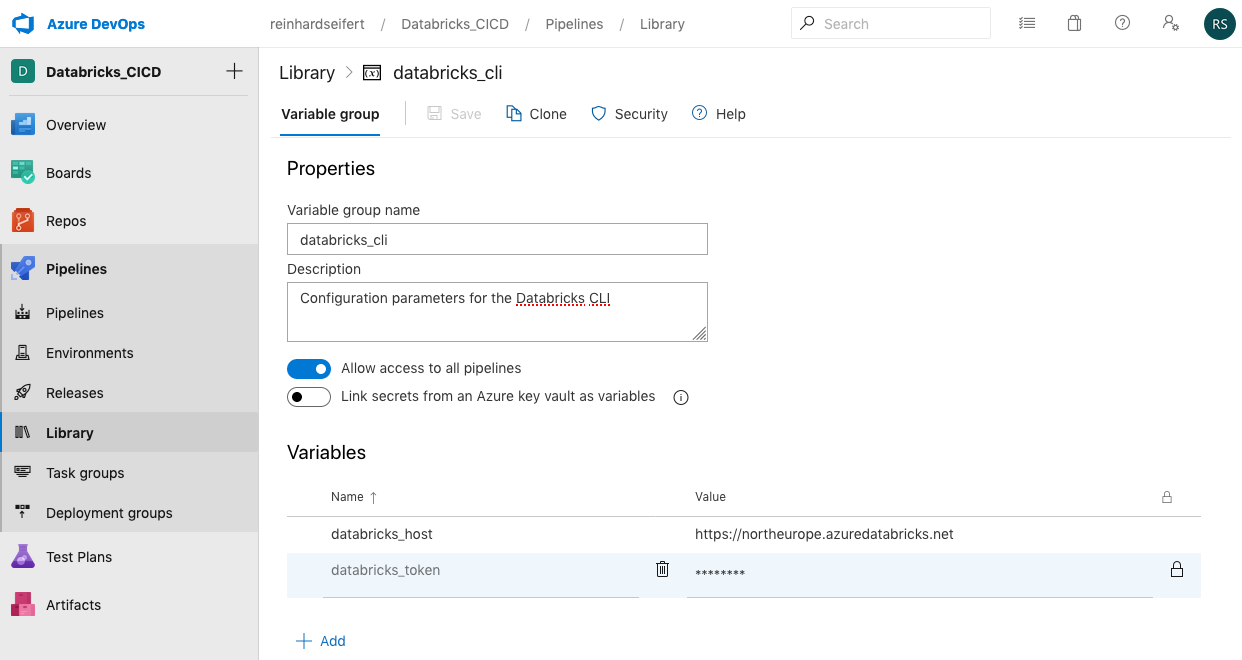
Pipelines > library > add variable group
Azure DevOps
Generally, the Azure DevOps portal offers minimal functionality a git repository to maintain code and pipelines to deploy the code from the repository into runtimes.
Azure repositories
The Azure repo contains the full logic of the integration:
- The actual (Python) code to run
- The JSON specification of the Spark cluster which will run the code
- Shell build scripts which are executed in the pipeline/build server
- The YAML configuration which defines the pipelines.
The complete CI/CD pipeline is contained in a single Git repository in a very compact fashion. Following Databricks’ terminology the Python code (1) is located in the workspace/directory. The runtime specification .json (2), build scripts .sh (3) and the pipeline configuration .yml (4) are located in the pipelines/directory according to the Azure DevOps paradigm.
Azure pipelines
The pipelines menu provides the following functionality:
- Pipelines (aka build pipelines)
- Environments (needed to group Azure resources – not used here)
- Releases (aka release pipelines – not used here)
- Library (containing the variable groups)
The build pipelines exclusively used in this demo project are managed under the “Pipelines > Pipelines” menu tab – not really intuitive.
Azure build pipelines
The pipeline’s build agents are configured via YAML files (e.g. build-cluster.yml). In this case, they install the Databricks CLI on the build machine and then execute CLI commands to create runtimes and move code notebooks to the runtime. The Databricks cluster is configured by a single JSON file (see config.cluster.json).
This minimal integration requires the creation of two pipelines:
- cluster creation – referencing pipelines/build-cluster.yml and
- workspace synchronization – referencing /pipelines/build-workspace.yml
After importing the repo:
- Select the pipelines > pipelines menu tab
- Choose Azure Repos Git YAML
- Select the imported repository from the drop-down menu
- Select Existing Azure Pipeline YAML file
- Select the YAML file from the drop-down menu
- Run the pipeline for the first time – or just save it and run it later.
At this point, the Databricks secret access token mentioned in the prerequisite paragraph needs to be present in a “databricks_cli” variable group. Otherwise, the pipeline run will fail and warn; in this case, just create the token (in Databricks) and the variable group (in DevOps) and re-run the pipeline.
After creating the pipelines and saving them (or running them initially), the default pipeline names reference the source repository name which triggers them. For easier monitoring the pipelines should be renamed according to their function, like “create-cluster” and “sync-workspace” in this case.
Summary
This concludes the integration of analytic code from an Azure DevOps repository into a hosted Databricks runtime.
Any change to the config.cluster.json deletes the existing cluster and creates a new one according to the specifications in the JSON file.
Any change to the workspace/ will copy the notebook file(s) (R, Python, Scala) to the Databricks workspace for execution on the cluster.
The Databricks workspace in this example was hosted on Azure. Only minor changes are required to use an AWS-hosted workspace. On all cloud platforms, the host URL and security token are specific for the chosen instance and region. The cloud-specific parameter is the node_type_id in the cluster configuration .json file.
Using this skeleton repo as a starting point, it is immediately possible to run interactive workloads on a performant Apache Spark cloud cluster – instead of “cooking” the local laptop with analytic code – transparently maintained on a professional DevOps platform.
Appendix
Following, a detailed walk-through of the .yml pipeline configurations, .sh build scripts and .json configuration files.
In general, the YAML instructs the build server to 1. start up when a certain file is changed (trigger), 2. copy the contents of the repository to the build server and 3. execute a selection of shell scripts (tasks) from the repository.
Pipeline: Create a cluster
This is a detailed walk-through for the build-cluster.yml pipeline. The .yml files have a hierarchical structure and the full hierarchy of the DevOps build pipeline is included although stages could be omitted.
Trigger
The first section of the pipeline YAML specifies the trigger. Any changes to the specified branch of the linked repo will automatically run off the build agent.
trigger: branches: include: – master paths: include: – pipelines/config.cluster.json – pipelines/databricks-library-install.sh
Without the paths: section, any change to the master branch will run the pipeline. The cluster is rebuild when the configuration changes or the selection of installed Python- or R-libraries changes.
Stages
The stage can be omitted (for a single stage pipeline) and the pool, variables and jobs directly defined. Then the stage would be implicit. It is possible to add testing steps to the pipeline and build fully automated CI/CD pipelines accross environments within on .yml file.
stages:
– stage: “dev”
displayName: “Development”
dependsOn: []
Pool
pool:
vmImage: “ubuntu-latest”
Selects the type of virtual machine to start when the trigger files are changed. At the time of writing ubuntu_latest will start a Ubuntu 18.04 LTS image.
Variables
variables:
– group: databricks_cli
This section references the variable group created in the Prerequisite section. The secret token is transfered to the build server and authorizes the API calls from the server to the Databricks workspace.
Jobs, steps and tasks
A job is a sequence of steps which are executed on the build server (pool). In this pipeline only task steps are used (see the docs for all step operations).
jobs:
– job: CreateCluster4Dev
steps:
– task: UsePythonVersion@0
inputs:
versionSpec: “3.8”
architecture: “x64”
The first step is selecting the Python version for all following Python command on the build server; the Databricks CLI is written in Python and installed via Pip in the following task.
Task: Install and configure the Databricks CLI
– task: ShellScript@2
inputs:
scriptPath: pipelines/databricks-cli-config.sh
args: “$(databricks_host) $(databricks\_token)”
displayName: “Install and configure the Databricks CLI”
Note that the path is relative to the root of the repo. The secret access token and host URL from the DevOps library are copied into environment variables which can be passed to the script in the args section.
The shell script executes the installation of the Databricks CLI and writes the neccessary CLI configuration on the build server.
python -m pip install databricks-cli
echo -e “[DEFAULT]\nhost: $HOST\ntoken: $TOKEN” > $HOME/.databrickscfg
Task: “Delete previous cluster version (if existing)”
This task will remove any cluster with the name provided in the args: section. This allows for updating the cluster when the configuration file is changed. When no such cluster is present the script will fail. Usually the pipeline will break at this point but here continueOnError is true, so the pipeline will continue when creating a cluster for the first time.
– task: ShellScript@2
inputs:
scriptPath: pipelines/databricks-cluster-delete.sh
args: “HelloCluster”
continueOnError: “true”
displayName: “Delete previous cluster version (if existing)”
The shell script called by this task is a wrapper around the Databricks CLI. First it queries for the cluster-id of any cluster with the name passed.
CLUSTER_ID=$(databricks clusters list –output json | jq -r –arg N “$CLUSTER_NAME” ‘.clusters[] | select(.cluster_name == $N) | .cluster_id’)
It is possible to create multiple clusters with the same name. In case there are multiple all of them are deleted.
for ID in $CLUSTER_ID
do
echo “Deleting $ID”
databricks clusters permanent-delete –cluster-id $ID
done
Task: Create new cluster
– task: ShellScript@2
inputs:
scriptPath: pipelines/databricks-cluster-create.sh
args: “HelloCluster”
displayName: “Create new cluster”
The build script reads the config.cluster.json and adds the cluster name passed from the pipeline .yml
cat config.cluster.json | sed “s/CLUSTER_NAME/$CLUSTER_NAME/g” > /tmp/conf.json
Now the configuration .json file can be passed to the Databricks CLI. The complete Apache Spark infrastructure is configured in the json. CLUSTER_NAME will be replaced with the name passed from the .yml.
{
“cluster_name”: “CLUSTER_NAME”,
“spark_version”: “6.0.x-scala2.11”,
“spark_conf”: {
“spark.sql.execution.arrow.enabled”: “true”
},
“node_type_id”: “Standard_DS3_v2”,
“num_workers”: 1,
“ssh_public_keys”: [],
“custom_tags”: {
“Project”: “DevOpsIntegration”
},
“cluster_log_conf”: {
“dbfs”: {
“destination”: “dbfs:/cluster_logs”
}
},
“spark_env_vars”: {
“PYSPARK_PYTHON”: “/databricks/python3/bin/python3”
},
“autotermination_minutes”: 120,
“enable_elastic_disk”: false,
“init_scripts”: []
}
Updating the runtime to another version requires only modifying the spark_version parameter with any supported runtime.
A Spark cluster consists of one driver node and a number of worker nodes and can be scaled horizontally by adding nodes (num_workers) or vertically by choosing larger node types. The node types are cloud provider specific. The Standard_DS3_v2 node type id references the minimal Azure node.
The autotermination feature shuts the cluster down when not in use. Costs are billed per second up time per processing unit.
Any reconfigurations triggers the pipeline and rebuilds the cluster.
CLUSTER_ID=$(databricks clusters create –json-file /tmp/conf.json | jq -r ‘.cluster_id’)
The cluster create call returns the cluster-id of the newly created instance. Since the last step of this pipeline installs additional Python and R libraries (via Pip and CRAN respectively) it is necessary to wait for the cluster to be in pending state.
STATE=$(databricks clusters list –output json | jq -r –arg I “$CLUSTER_ID” ‘.clusters[] | select(.cluster_id == $I) | .state’)
echo “Wait for cluster to be PENDING”
while [[ “$STATE” != “PENDING” ]]
do
STATE=$(databricks clusters list –output json | jq -r –arg I “$CLUSTER_ID” ‘.clusters[] | select(.cluster_name == $I) | .state’)
done
Task: Install Python and R dependencies on the cluster
The final step is to add additional Python and R packages to the cluster. There are many ways to install packges in Databricks. This is just one way to do it.
– task: ShellScript@2
inputs:
scriptPath: pipelines/databricks-library-install.sh
args: “HelloCluster”
displayName: “Install Python and R dependencies”
Again the shell script wraps the Databricks CLI, here the library install command. The cluster name (“DemoCluster” in this example) has to be passed again.
All CLI calls to Databricks need the cluster-id to delete, create and manupulate instances. So first fetch it with a cluster list call:
CLUSTER_ID=$(databricks clusters list –output json | jq -r –arg N “$CLUSTER_NAME” ‘.clusters[] | select(.cluster_name == $N) | .cluster_id’)
Then install the packages – one call to library install per package:
databricks libraries install –cluster-id $CLUSTER_ID –pypi-package azure
databricks libraries install –cluster-id $CLUSTER_ID –pypi-package googlemaps
databricks libraries install –cluster-id $CLUSTER_ID –pypi-package python-tds
databricks libraries install –cluster-id $CLUSTER_ID –cran-package tidyverse
For additional Python or R package add a line in this build script – this will trigger the pipeline and the cluster is rebuild.
Pipeline: Import workspace
This is a detailed walk through for the build-workspace.yml pipeline. The first part of the pipeline is identical to the build-cluster.yml pipeline. The trigger include differs, since this pipeline is triggered by code pushes to the workspace/ directory. The choice of the build server (pool), the variable reference to the databricks_cli variable group for the Databricks access tokens and the Python version task are identical, also installing and configuring the Databricks CLI with the same build script as above.
The only build task is importing all files in the workspace/ directory to the Databricks Workspace. The args passes a sub-directory name for the /Shared/ folder in Databricks ( /Shared/HelloWorkspace/ in the example).
– task: ShellScript@2
inputs:
scriptPath: pipelines/databricks-workspace-import.sh
args: “HelloWorkspace”
displayName: “Import updated notebooks to workspace to dev”
The specified directory is first deleted. When the directory does not exist, the CLI prints and error in JSON format, but does not break the pipeline. The args: parameter is passed to the $SUBDIR variable in the build script.
databricks workspace delete –recursive /Shared/$SUBDIR
Then the script files in the workspace/ folder of the master branch are copied into the Databricks workspace.
databricks workspace import_dir ../workspace /Shared/$SUBDIR/
Remember that the repo is copied into the pipeline build agent/server and the working directory of the pipeline agent points to the location of the .yml file which defines the pipeline.