DSPy a better way to build transparent, sustainable AI systems
Mohamed ElnamouryMachine Learning Engineer
Published 22 Oct 2025
Reading time 6 min
Developing an AI application is never just about picking the right model, it’s about context. It depends on how well your data is prepared, how your agentic system is structured for the task, and, too often, how long your prompts are. But what if, instead of spending endless hours crafting and tweaking prompts, we started by building the skeleton of the solution first?
We define the components, clarify what we want to achieve, and prepare examples of how the LLM should behave. Once the structure is in place (the components, the technology stack, and the dataset), we can use any LLM we want. Instead of thinking “How should I phrase this prompt?”, we think “What system am I building?” Then, let’s let the LLM write the prompt for us.
Let’s make it systematic, modular, declarative, and optimisable.
Why DSPy? Pain points with prompt engineering
Prompting LLMs allows anyone to describe a task quickly.
Let the LLM write your prompt
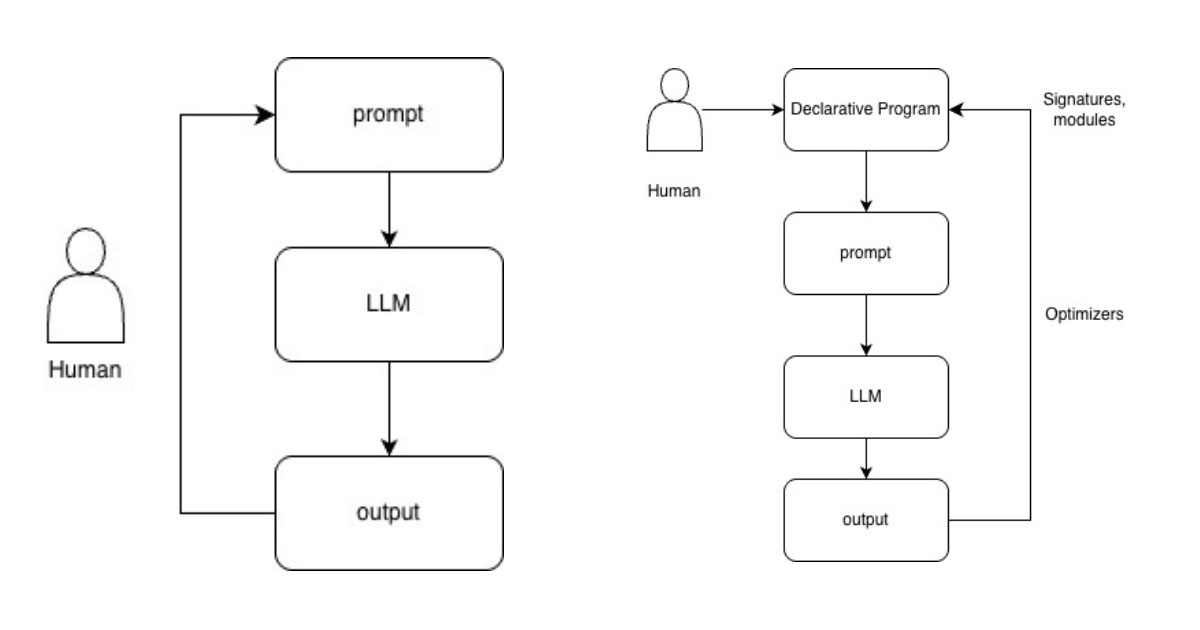
The traditional approach typically involved spending more time crafting the prompt for the task, which was a process of guesswork and trial and error. It was brittle and hard to optimise. Tracking changes to the prompt can be painful and annoying, and differs from one model to another.
Image: Manual prompting and DSPy pipeline
But what if we shifted our focus to not spending time there, and we spent the time designing a dataset (Evals) for our solution? As humans developing the app, we are better at defining the goal of the solution and what kind of input X leads to output Y, X → Y. What if we treat the LLM as a function that can be tweaked and twisted, as we did before with the traditional machine learning process?
Let’s now explore how DSPy can be the key enabler in such a case. But what is DSPy? It’s a framework to convert the prompt into programmatic instructions. It treats the LLMs pipelines as programs to be compiled. So, how do we tell DSPy how our program should work?
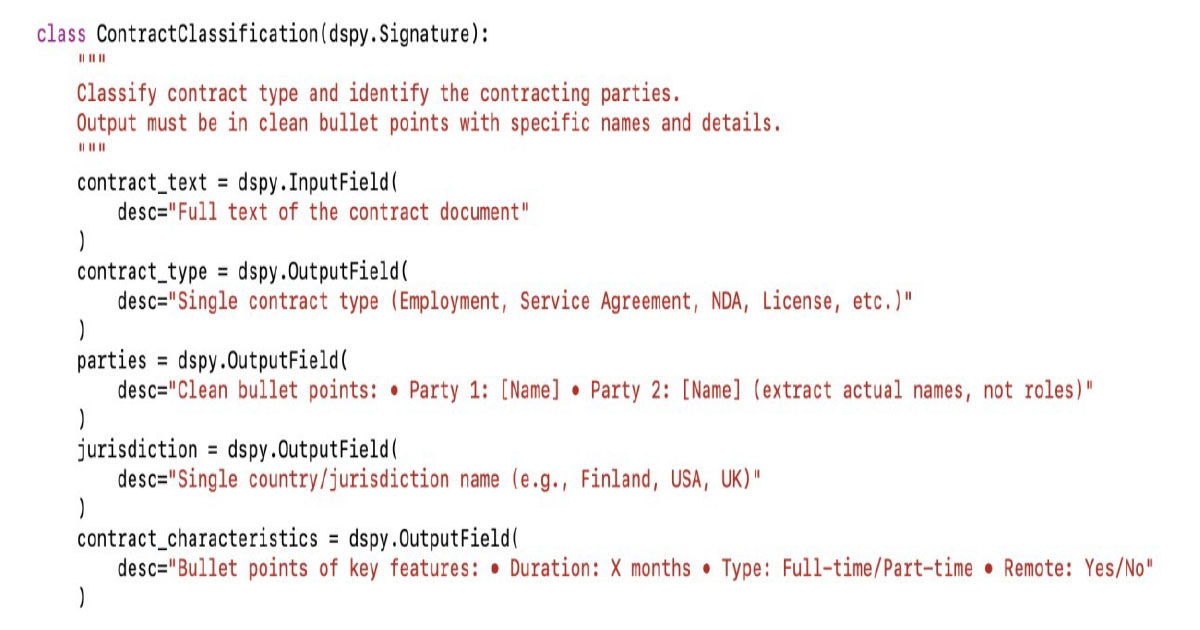
You start defining the program structure with a signature which is the simple declarations of how your LLM task in this section you convert the very long text into your prompt into direct straight forward programable commands that anyone with programming background can read but here we are not also eliminating the simplicity of reading the prompt we preserve this advantage but in a programmatic way, let’s have a quick example of how a prompt can be converted using DSPy
Prompt vs signature
So, looking at the example below, this is how you can achieve the same prompt by writing in a more precise and declarative way. You start simple, then you build on top of this with the rest of DSPy’s capabilities.
Normal prompt:
Signature:
Modules and examples creation
But how can we get this signature work? How can we get it to fit in our solution?
DSPy provides different inference techniques that could fit into your tasks. For the example above, I wanted to achieve consistent output so I could convert the documents into a systematic way. I used to predict module as simply as the next picture shows, but DSPy has other modules to use (ChainOfThoughts, ReAct,CodeAct). To get this systematic output, I needed to create a dataset that would help me guide the LLM to execute a specific task.
Examples or datasets can be used to guide your workflow better
But what could those examples look like:
Pair of questions for RAG
Examples of multi-label classification
Customised examples for your workflow and how it should be executed
Each set of those examples above could be utilised using a specific module of DSPy:
ReAct for agentic workflows and tool calling
Predict for classification
Chain of thought for reasoning capabilities
What comes next after setting initial examples for your solution?
Optimising for reliability
For the next step of our development and the cool part of DSPy, now with a dataset created, we can run the optimisers provided by DSPy. Its optimisers are algorithms that will write the prompt for us, and it will instruct the LLM better by running through different examples till it reaches the optimal point. But what do optimisers bring to the table?
Optimisers are algorithms that treat LLMs as black boxes based on your input examples and preferred outputs. You can define an evaluation metric for those optimisers and use it to direct the LLM by writing a more suitable prompt that can be extracted, versioned and even rerun and generated again for different types of LLMs. I won’t deep dive into the algorithms, but let’s have a quick look at their latest and most capable optimiser GEPA. Before this, let’s take a step back and investigate what optimisers bring to the table compared to GRPO “RL”.
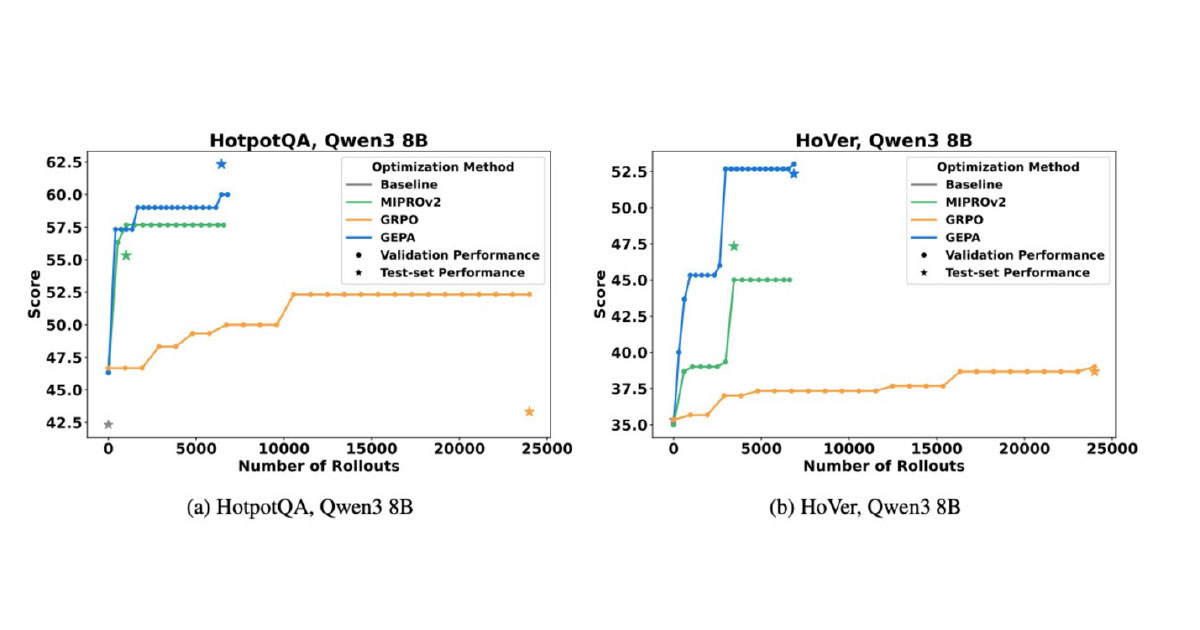
For an experiment that has been conducted on two of the most famous datasets, HotpotQA and HoVer, both GEPA and MIPROv2 “prompt optimisation algorithm” scored better results and improvement compared to GRPO, which requires more computational resources and money.
Image: HotpotQA and HoVer
But what is GEPA?
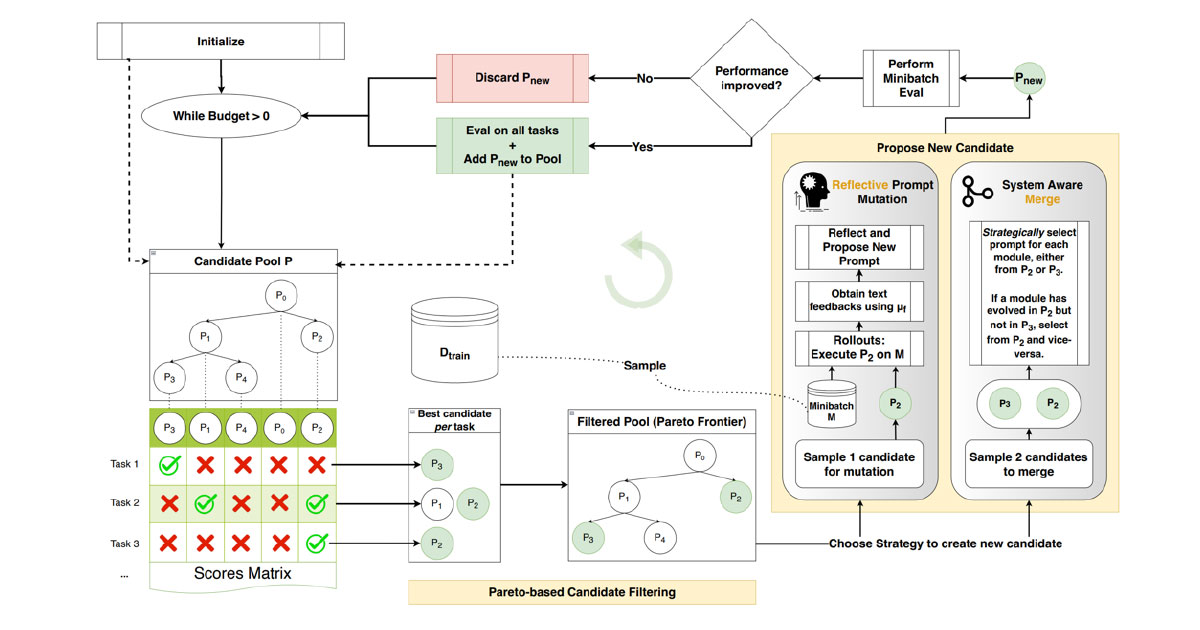
The most advanced optimiser in DSPy is GEPA (Genetic-Pareto), which introduces a novel, reflective mechanism for prompt evolution. Unlike traditional optimisers, GEPA treats the LLM as a partner in the optimisation process. It samples various prompt “trajectories” and then prompts the LLM itself to reflect on the outcomes in natural language. This introspection allows the system to diagnose problems, propose concrete prompt updates, and test them iteratively. By identifying and combining the most successful strategies from its exploration — a technique inspired by Pareto efficiency — GEPA converges on superior prompts with remarkable speed. This methodological breakthrough translates to tangible gains: GEPA outperforms reinforcement learning (GRPO) by up to 20% with 35x fewer rollouts and exceeds its predecessor (MIPROv2) by over 10% on key benchmarks.
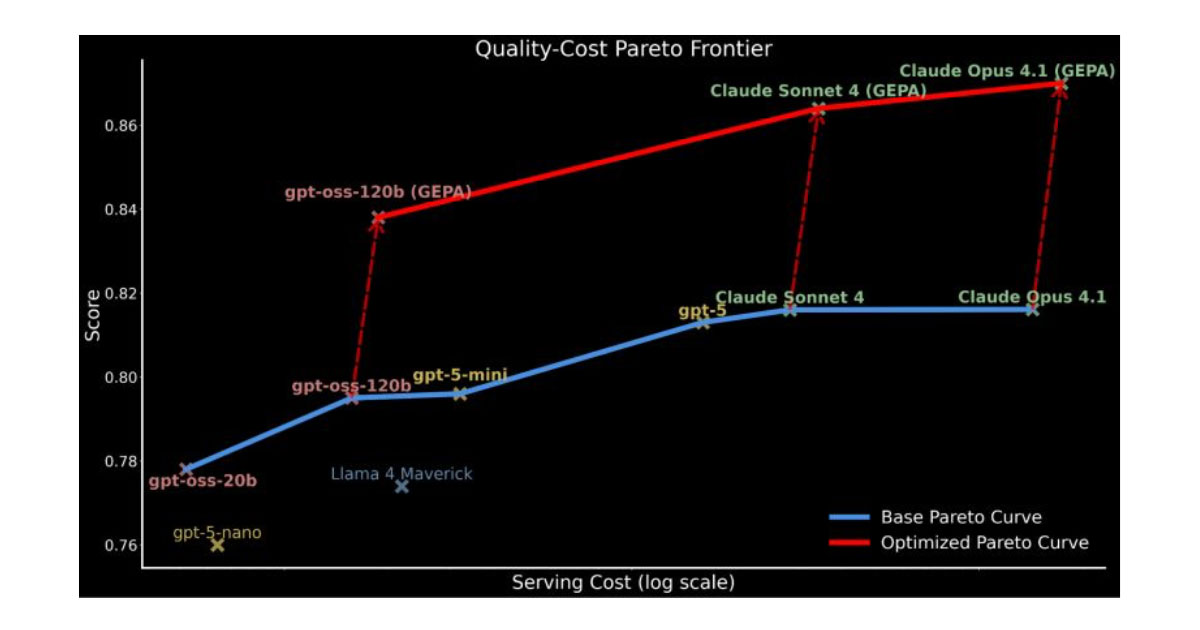
Running optimisers against your predefined examples can help increasing the accuracy and more consistent output. Let’s have a look into how this can be achieved in production in terms of quality and cost.
Looking into the chart we can see that Databricks using prompt optimisation on information extraction (IE) managed to make open source compete with closed source expensive models like Claude Opus 4.1.
And within Solita using DSPy with GPT4.1 mini for information extraction helped us to achieve more consistent results with cheaper cost.
You can see from the above example we improvement that help us build more reliably.
By combining all the dots together and building reusable pipeline that can be optimised for different LLMs this leads to a more sustainable and reusable solutions, it unlocks the capabilities to choose smaller models and test it against bigger tasks.
Monitoring & observability
Since most of agree that building a reliable and reusable solution requires defining a proper metrics and since those metrics and crucial for unlocking the capabilities of prompt optimisation, we can even collect those metrics for future usage: such as monitoring, memory management or even fine-tuning smaller models for specific tasks.
DSPy allows you monitor your workflows through MLflow, or you can setup you monitoring technique in your preferred way. But ensuring this means your solution is now well defined and more reliable against changes over times.
Lessons learned & next steps
Our experience with DSPy has yielded several key advantages:
Sustainability and reproducibility: In a fast-paced environment, DSPy provides a framework for building solutions that are maintainable and can be reliably reproduced.
Model agnosticism: DSPy programs can run with any LLM from any cloud provider, giving you the flexibility to adapt as the landscape evolves.
Component reusability: Optimised DSPy components can be saved, versioned, and loaded for future use, accelerating development.
Seamless integration: Compatibility with tools like MLflow makes tracking and versioning a straightforward part of the workflow.
Looking ahead, the DSPy framework is rapidly evolving. The introduction of asynchronous task execution will be a major boon for deploying high-performance, scalable solutions in production environments.